8 Dados relacionais
8.1 Introdução
Em diversas situações, precisamos utilizar informações provenientes de diferentes bases de dados, como no caso de planilhas Excel distintas. Para isso, é necessário juntar todas as informações em um único data frame.
O pacote dplyr oferece diversas funções que facilitam esse processo. Neste capítulo, apresentaremos as funções das famílias bind_() e _join().
Usaremos a planilha dados-juntar.xlsx para os exemplos. Para fazer o download do arquivo, clique aqui.
library(readxl)
excel_sheets("dados/dados-juntar.xlsx")
#> [1] "dados1" "dados2" "dados3" "dados4" "dados5"Com a função excel_sheets(), verificamos que a planilha contém 5 abas, todas relacionadas a um mesmo tema, que precisamos consolidar em um único data frame. Assim, devemos carregar cada aba da planilha em objetos distintos.
d1 <- read_excel("dados/dados-juntar.xlsx", sheet = "dados1")
d1
#> # A tibble: 2 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Amanda F 25 63
#> 2 Maria F 30 65
d2 <- read_excel("dados/dados-juntar.xlsx", sheet = "dados2")
d2
#> # A tibble: 2 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Vitor M 24 73
#> 2 Leticia F 23 52
d3 <- read_excel("dados/dados-juntar.xlsx", sheet = "dados3")
d3
#> # A tibble: 2 × 4
#> sexo nome peso idade
#> <chr> <chr> <dbl> <dbl>
#> 1 F Vitoria 51 21
#> 2 M Marcos 68 18
d4 <- read_excel("dados/dados-juntar.xlsx", sheet = "dados4")
d4
#> # A tibble: 2 × 4
#> nomes sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Julio M 25 72
#> 2 Fabio M 35 81
d5 <- read_excel("dados/dados-juntar.xlsx", sheet = "dados5")
d5
#> # A tibble: 8 × 2
#> nome profissao
#> <chr> <chr>
#> 1 Fabio Medico
#> 2 Gabriel Estudante
#> 3 Guilherme Cozinheiro
#> 4 Jose Biologo
#> 5 Julio Zootecnista
#> 6 Marcos Professor
#> 7 Vitor Agronomo
#> 8 Getulio Musico
8.2 Funções bind_()
As funções do tipo bind_() são as mais simples para combinar conjuntos de dados. A função bind_rows() permite unir as observações (linhas) de dois ou mais data frames com base nas colunas. Essa abordagem é útil quando os conjuntos de dados compartilham a mesma estrutura de variáveis (colunas), mas contêm observações diferentes.
Com essa função, podemos realizar a união dos data frames d1, d2, d3 e d4, que possuem as mesmas variáveis, porém tratando de diferentes observações.
Primeiramente, uniremos as bases d1 e d2. Para isso, utilizamos a função bind_rows(), declarando os data frames que desejamos combinar, separados por vírgula.
d1_d2 <- bind_rows(d1, d2)
d1_d2
#> # A tibble: 4 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Amanda F 25 63
#> 2 Maria F 30 65
#> 3 Vitor M 24 73
#> 4 Leticia F 23 52Uma vez unidos os dados de d1 e d2, juntaremos com o d3. Note que as colunas do data frame d3 apresentam uma ordem diferente em relação às de d1 e de d2. Apesar disso, a função bind_rows() consegue combinar as linhas de maneira adequada, desde que os nomes das colunas dos conjuntos de dados sejam iguais.
d1_d2_d3 <- bind_rows(d1_d2, d3)
d1_d2_d3
#> # A tibble: 6 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Amanda F 25 63
#> 2 Maria F 30 65
#> 3 Vitor M 24 73
#> 4 Leticia F 23 52
#> 5 Vitoria F 21 51
#> 6 Marcos M 18 68A função bind_rows() também consegue juntar mais de dois conjuntos de dados em um só comando. Basta declararmos os data frames que desejamos combinar.
d1_d2_d3_d4 <- bind_rows(d1, d2, d3, d4)
d1_d2_d3_d4
#> # A tibble: 8 × 5
#> nome sexo idade peso nomes
#> <chr> <chr> <dbl> <dbl> <chr>
#> 1 Amanda F 25 63 <NA>
#> 2 Maria F 30 65 <NA>
#> 3 Vitor M 24 73 <NA>
#> 4 Leticia F 23 52 <NA>
#> 5 Vitoria F 21 51 <NA>
#> 6 Marcos M 18 68 <NA>
#> 7 <NA> M 25 72 Julio
#> 8 <NA> M 35 81 FabioJuntando os dados de d4 com os dados de d1, d2 e d3, percebemos que foi criada uma nova coluna. Isso ocorre pois a nomenclatura atribuída à variável nome no d4 está no plural. Sendo assim, precisamos padronizar o nome dessa variável antes de juntá-la às demais utilizando a função rename() (vide Seção 7.3.2).
d1_d2_d3_d4 <- bind_rows(d1, d2, d3, d4_corrigido)
d1_d2_d3_d4
#> # A tibble: 8 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Amanda F 25 63
#> 2 Maria F 30 65
#> 3 Vitor M 24 73
#> 4 Leticia F 23 52
#> 5 Vitoria F 21 51
#> 6 Marcos M 18 68
#> 7 Julio M 25 72
#> 8 Fabio M 35 81Dessa forma, ao realizar a junção dos quatro conjuntos de dados, os nomes são alocados em uma única coluna (nome).
De modo análogo à bind_rows(), a função bind_cols() une colunas de dois ou mais conjuntos de dados. A seguir, juntaremos as colunas dos data frames d1_d2_d3_d4 e d5.
d1_d2_d3_d4_d5 <- bind_cols(d1_d2_d3_d4, d5)
d1_d2_d3_d4_d5
#> # A tibble: 8 × 6
#> nome...1 sexo idade peso nome...5 profissao
#> <chr> <chr> <dbl> <dbl> <chr> <chr>
#> 1 Amanda F 25 63 Fabio Medico
#> 2 Maria F 30 65 Gabriel Estudante
#> 3 Vitor M 24 73 Guilherme Cozinheiro
#> 4 Leticia F 23 52 Jose Biologo
#> 5 Vitoria F 21 51 Julio Zootecnista
#> 6 Marcos M 18 68 Marcos Professor
#> 7 Julio M 25 72 Vitor Agronomo
#> 8 Fabio M 35 81 Getulio MusicoNote que a função juntou as colunas, preservando todas as variáveis, bem como a ordem original das linhas das bases de dados. Porém, nesse caso, seria conveniente unir as colunas com base na variável em comum entre os conjuntos, no caso, a variável nome. Para isso, utilizamos um outro conjunto de funções, as do tipo _join.
8.3 Funções _join()
As funções da família _join() (também conhecidas por merge) são utilizadas para combinar data frames com base em uma ou mais colunas em comum. Elas são úteis quando precisamos integrar dados complementares provenientes de diferentes fontes. A figura Figura 8.1 ilustra as possíveis operações a serem realizadas.
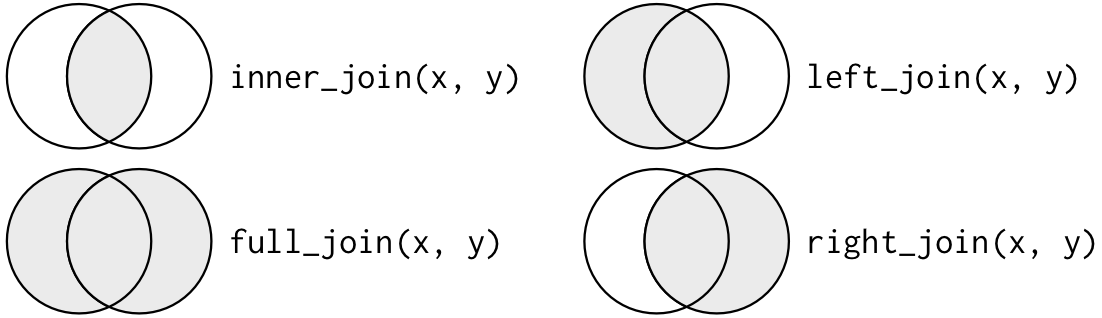
Fonte: R for Data Science, 2017.
No exemplo anterior, você deve ter notado que o data frame d5 possui observações em comum com o d1_d2_d3_d4, mas também, diferentes. Nesse caso, de acordo com o interesse da análise, podemos proceder de diferentes maneiras.
8.3.1 inner_join()
A função inner_join() retorna apenas as observações em comum entre dois conjuntos de dados, de acordo com certa variável.
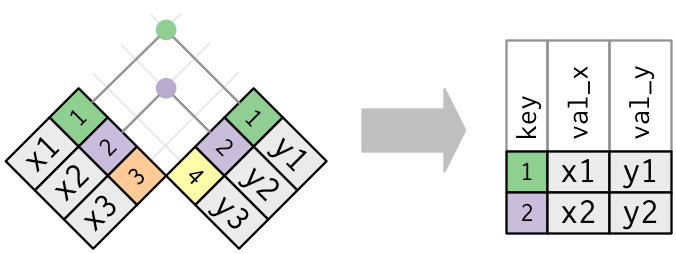
Fonte: R for Data Science, 2017.
d_inner <- inner_join(x = d1_d2_d3_d4, y = d5, by = "nome")
d_inner
#> # A tibble: 4 × 5
#> nome sexo idade peso profissao
#> <chr> <chr> <dbl> <dbl> <chr>
#> 1 Vitor M 24 73 Agronomo
#> 2 Marcos M 18 68 Professor
#> 3 Julio M 25 72 Zootecnista
#> 4 Fabio M 35 81 MedicoNa função acima, declaramos os dois data frames a serem combinados, junto ao argumento by = "nome", ou seja, a variável em comum. Como resultado, a inner_join() nos retornou apenas as observações em comum entre os conjuntos de dados, em relação à coluna nome.
Caso haja mais de uma variável em comum, basta declarar um vetor com as variáveis no argumento by = (by = c("var_1", "var_2", ..., "var_n")). Atente-se ao fato que as variáveis devem estar entre aspas.
8.3.2 full_join()
A função full_join() nos retorna todas as observações de ambos os data frames, atribuindo o valor NA quando não houver correspondência em um deles.
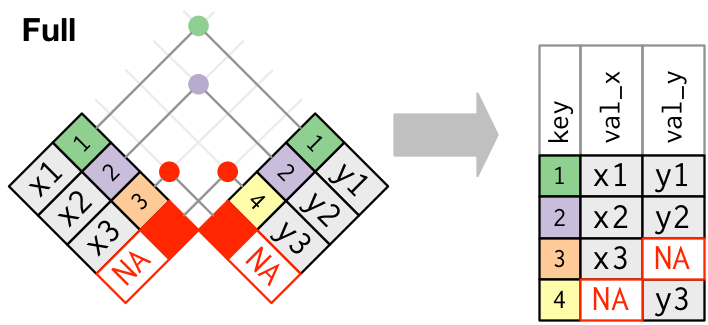
Fonte: R for Data Science, 2017.
d_full <- full_join(x = d1_d2_d3_d4, y = d5, by = "nome")
d_full
#> # A tibble: 12 × 5
#> nome sexo idade peso profissao
#> <chr> <chr> <dbl> <dbl> <chr>
#> 1 Amanda F 25 63 <NA>
#> 2 Maria F 30 65 <NA>
#> 3 Vitor M 24 73 Agronomo
#> 4 Leticia F 23 52 <NA>
#> 5 Vitoria F 21 51 <NA>
#> 6 Marcos M 18 68 Professor
#> 7 Julio M 25 72 Zootecnista
#> 8 Fabio M 35 81 Medico
#> 9 Gabriel <NA> NA NA Estudante
#> 10 Guilherme <NA> NA NA Cozinheiro
#> 11 Jose <NA> NA NA Biologo
#> 12 Getulio <NA> NA NA Musico
8.3.3 left_join() e right_join()
A função left_join() mantém todas as observações do primeiro conjunto declarado (x =) e adiciona os valores em comum do segundo conjunto (y =).
Por outro lado, a right_join() retorna todas as observações do segundo conjunto (y =) e adiciona os valores em comum do primeiro conjunto (x =).
Caso não haja correspondência entre os conjuntos, serão atribuídos valores NA.
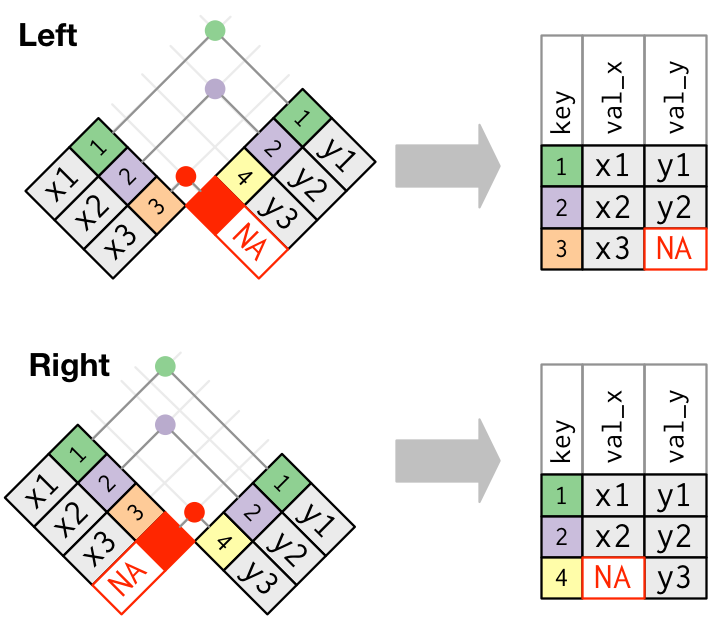
Fonte: R for Data Science, 2017.
d_left <- left_join(x = d1_d2_d3_d4, y = d5, by = "nome")
d_left
#> # A tibble: 8 × 5
#> nome sexo idade peso profissao
#> <chr> <chr> <dbl> <dbl> <chr>
#> 1 Amanda F 25 63 <NA>
#> 2 Maria F 30 65 <NA>
#> 3 Vitor M 24 73 Agronomo
#> 4 Leticia F 23 52 <NA>
#> 5 Vitoria F 21 51 <NA>
#> 6 Marcos M 18 68 Professor
#> 7 Julio M 25 72 Zootecnista
#> 8 Fabio M 35 81 Medico
d_right <- right_join(x = d1_d2_d3_d4, y = d5, by = "nome")
d_right
#> # A tibble: 8 × 5
#> nome sexo idade peso profissao
#> <chr> <chr> <dbl> <dbl> <chr>
#> 1 Vitor M 24 73 Agronomo
#> 2 Marcos M 18 68 Professor
#> 3 Julio M 25 72 Zootecnista
#> 4 Fabio M 35 81 Medico
#> 5 Gabriel <NA> NA NA Estudante
#> 6 Guilherme <NA> NA NA Cozinheiro
#> 7 Jose <NA> NA NA Biologo
#> 8 Getulio <NA> NA NA Musico
8.3.4 semi_join() e anti_join()
O semi_join() retorna apenas as observações do primeiro conjunto (x =) que também estão presentes no segundo conjunto (y =).
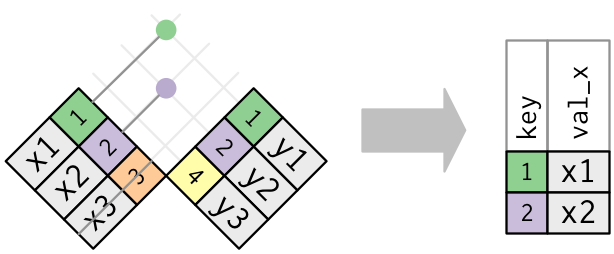
Fonte: R for Data Science, 2017.
# Tendo como primeiro conjunto o `d1_d2_d3_d4`
d_semi1 <- semi_join(x = d1_d2_d3_d4, y = d5, by = "nome")
d_semi1
#> # A tibble: 4 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Vitor M 24 73
#> 2 Marcos M 18 68
#> 3 Julio M 25 72
#> 4 Fabio M 35 81
# Tendo como primeiro conjunto o `d5`
d_semi2 <- semi_join(x = d5, y = d1_d2_d3_d4, by = "nome")
d_semi2
#> # A tibble: 4 × 2
#> nome profissao
#> <chr> <chr>
#> 1 Fabio Medico
#> 2 Julio Zootecnista
#> 3 Marcos Professor
#> 4 Vitor AgronomoJá o anti_join() retorna apenas as observações do primeiro conjunto (x =) que não estão presentes no segundo conjunto (y =).
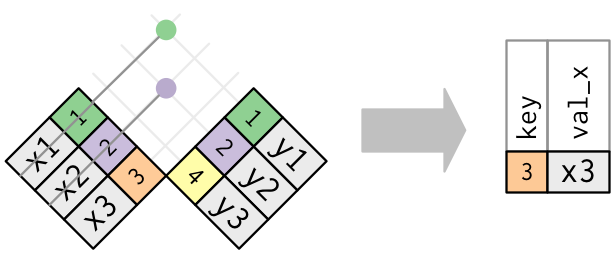
Fonte: R for Data Science, 2017.
# Tendo como primeiro conjunto o `d1_d2_d3_d4`
d_anti1 <- anti_join(x = d1_d2_d3_d4, y = d5, by = "nome")
d_anti1
#> # A tibble: 4 × 4
#> nome sexo idade peso
#> <chr> <chr> <dbl> <dbl>
#> 1 Amanda F 25 63
#> 2 Maria F 30 65
#> 3 Leticia F 23 52
#> 4 Vitoria F 21 51
# Tendo como primeiro conjunto o `d5`
d_anti2 <- anti_join(x = d5, y = d1_d2_d3_d4, by = "nome")
d_anti2
#> # A tibble: 4 × 2
#> nome profissao
#> <chr> <chr>
#> 1 Gabriel Estudante
#> 2 Guilherme Cozinheiro
#> 3 Jose Biologo
#> 4 Getulio MusicoAs funções semi_join() e anti_join(), diferentemente dos demais _joins() apresentados, não adicionam colunas de y = ao x = (ou vice-versa), mas filtram as colunas de x = com base em y =.
Dessa forma, semi_join() e anti_join() são conhecidas por filtering joins, pois filtram observações de um conjunto de dados com base na correspondência (ou não) às observações do outro conjunto, atuando de modo semelhante à função filter() (vide Seção 7.4.1). Por outro lado, inner_join(), full_join(), left_join() e right_join() são mutating joins, ou seja, adicionam novas variáveis a um conjunto de dados a partir de observações correspondentes em outro, atuam de maneira semelhante à função mutate() (vide Seção 7.3.4)
8.4 Resumo
A Tabela 8.1 traz um resumo das funções apresetadas neste capítulo.
bind_() e _join().
| Função | Uso |
|---|---|
bind_row() |
Combina linhas de dois ou mais conjuntos |
bind_col() |
Combina colunas de dois ou mais conjuntos |
inner_join() |
Combina linhas em comum entre conjuntos |
full_join() |
Combina todas as linhas entre conjuntos |
left_join() |
Mantém todas as linhas do primeiro conjunto e retorna os correspondentes do segundo conjunto |
right_join() |
Mantém todas as linhas do segundo conjunto e retorna os correspondentes do primeiro conjunto |
semi_join() |
Filtra as linhas do primeiro conjunto correspondentes ao segundo conjunto |
anti_join() |
Filtra as linhas do primeiro conjunto que não são correspondentes ao segundo conjunto |
As funções das famílias bind_() e _join() são essenciais para manipulação e integração de dados no R. Saber como utilizá-las nos auxilia no processo de análise, tornando-o mais eficiente e organizado.
Nos próximos capítulos, exploraremos técnicas mais específicas para a transformação de dados. Caso o leitor esteja iniciando seus estudos em R, recomendo que avance diretamente para o Capítulo 9, onde abordaremos a visualização de dados por meio de gráficos. À medida que ganhar mais familiaridade com a linguagem, você poderá retornar a esses capítulos para aprofundar seus conhecimentos com maior facilidade.