Fonte: Drew Conway, 2010 (Adaptado).
A ciência de dados, como o próprio termo sugere, consiste na extração de informações relevantes por meio da análise de dados, utilizando técnicas e conhecimentos multidisciplinares.
Nos últimos anos, o termo se tornou amplamente difundido em diversos meios, alcançando grande notoriedade devido à proliferação massiva de dados em elevada quantidade, diversidade e velocidade.
Como resultado, diversos setores reconheceram a necessidade de contar com profissionais qualificados para extrair informações a partir de dados, a fim de auxiliar em seu desenvolvimento.
Apesar da popularização recente, a concepção da ciência de dados remonta ao século passado, seja por figuras notáveis como o matemático e estatístico John W. Tukey, bem como indivíduos atuantes nos campos de negócios e pesquisa. Mesmo sem a intenção explícita de formar uma nova área do conhecimento, estes podem ser considerados os precursores da ciência de dados.
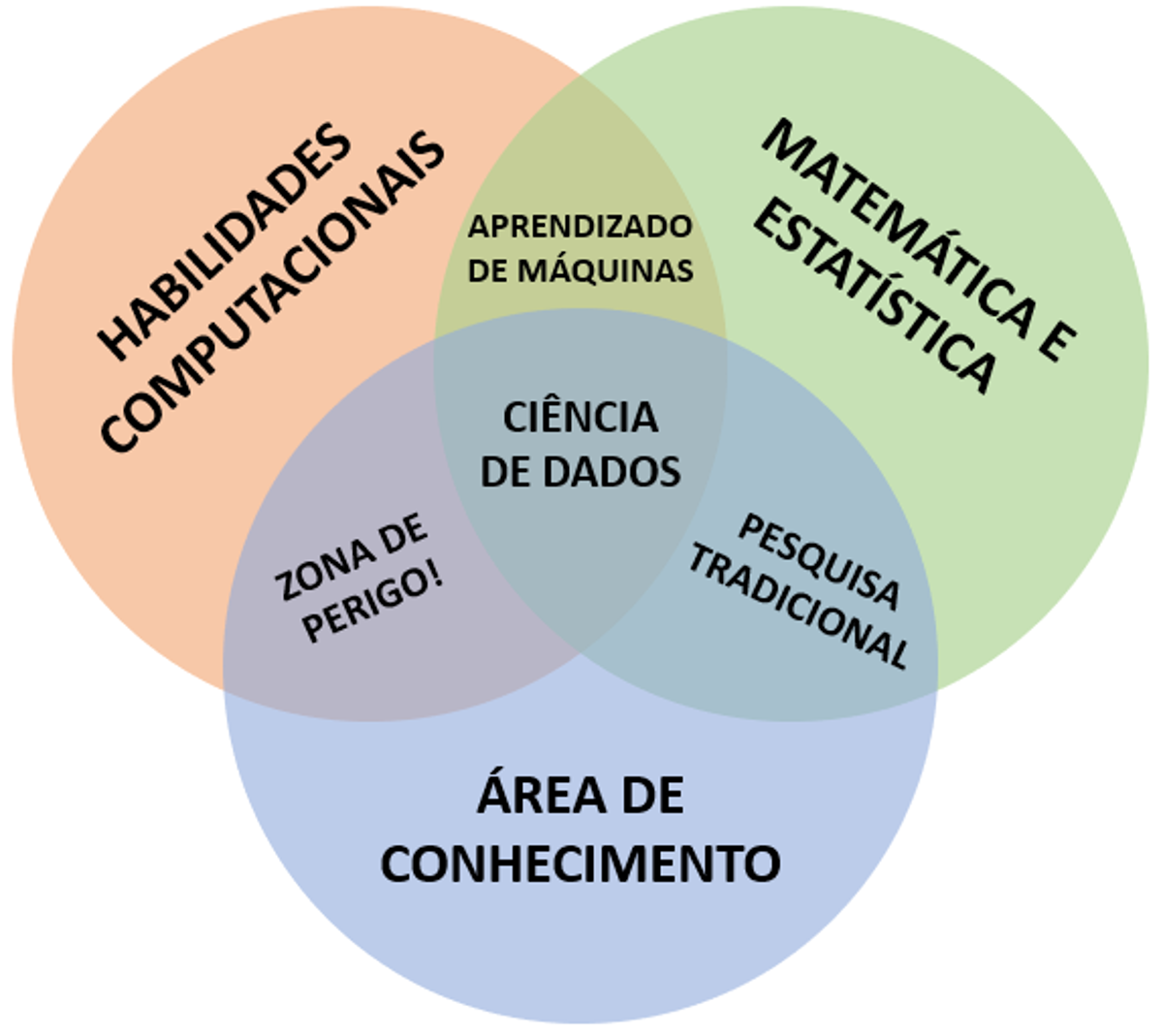
A concepção recente de ciência de dados abrange pelo menos três grandes áreas do conhecimento, podendo ser descrita por meio de um diagrama de Venn elaborado por Drew Conway e ilustrado na Figura 1.1.
O diagrama é composto pelo conjunto de habilidades computacionais, conhecimento de matemática e estatística e domínio da área de conhecimento. Assim, as intersecções entre os conjuntos resultam em certas habilidades, descritas da seguinte maneira:
Aprendizado de máquinas: do termo em inglês machine learning, consiste na intersecção entre as habilidades computacionais e de matemática e estatística. Utiliza estas bases para entender os modelos utilizados e detectar os padrões que serão replicados a partir dos artifícios da programação, com o intuito de colocar em prática os algoritmos.
Pesquisa tradicional: é a intersecção entre as áreas da matemática e estatística e área de conhecimento. Consiste na aplicação das bases matemáticas e estatísticas para solucionar problemas em uma área de atuação específica, sendo uma prática comum e tradicional no meio da pesquisa, principalmente a acadêmica.
Zona de perigo: a intersecção entre habilidades computacionais e área de conhecimento resulta em uma chamada zona de perigo, pois quem se encontra nesta situação consegue resolver problemas aplicando algoritmos, porém sem as bases teóricas da matemática e estatística para compreender ou averiguar os resultados.
Ciência de dados: a ciência de dados é o resultado da intersecção entre as três áreas - habilidades computacionais, matemática e estatística e área de conhecimento. Na prática, um cientista de dados não precisa ter total domínio destas três áreas. Normalmente, possui especialização em alguma das três, porém sabe aplicá-las para resolver problemas.
Tendo uma breve noção sobre o que se trata a ciência de dados, vamos explorar as etapas que compõem o seu processo.
O fluxograma da Figura 1.2 representa as etapas que compõem o trabalho de um cientista de dados. A seguir, descreveremos brevemente as etapas para termos noção sobre a relevância de cada uma delas.
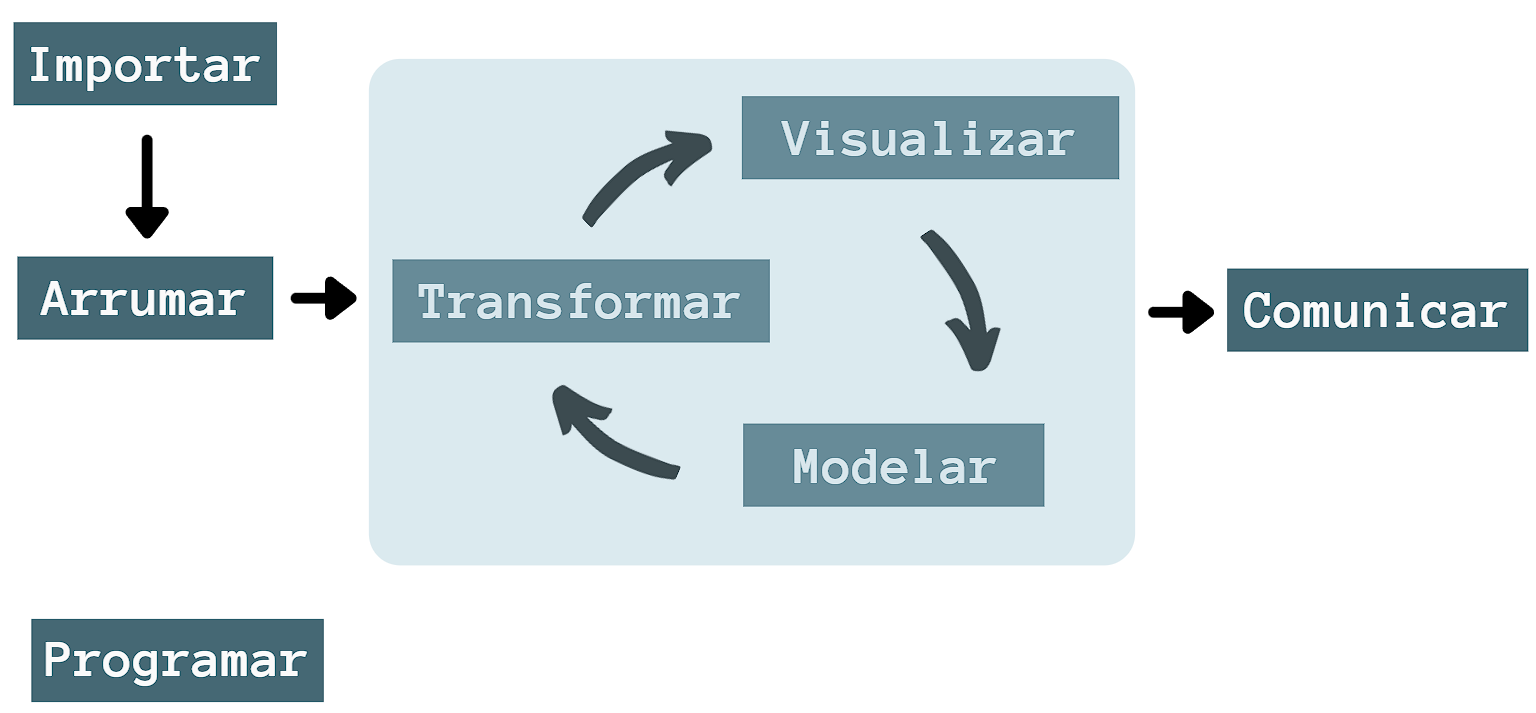
Importar (Import): é a importação dos dados para dentro do software (no nosso caso, o R), seja a partir de arquivos ou banco de dados presentes na web ou coletados pelo próprio cientista de dados. Basicamente é a etapa sine qua non da ciência de dados, pois sem dados, não há o que analisar. Trataremos desse assunto no Capítulo 4;
Limpar/Arrumar (Tidy): limpar ou arrumar os dados significa organizá-los em uma estrutura consistente, que esteja de acordo com a semântica de um conjunto de dados, a fim de evitar problemas ao realizar as análises. No Capítulo 5, veremos como estruturar os dados de maneira desejável, designando cada variável a uma coluna e cada observação a uma linha, semalhante a uma planilha Excel;
Transformar (Transform): a transformação consiste em selecionar as observações de interesse no banco de dados. Em outras palavras, reduzir o banco de dados para conter somente as informações necessárias para a análise. Também podemos criar novas variáveis em função das variáveis já existentes, além de gerar estatísticas como média, variância e proporções. Esta etapa será abordada no Capítulo 6 que está dividido em outros sete (Capítulos -Capítulo 7, -Capítulo 8, -?sec-numbers, -?sec-lubridate, -?sec-forcats, -?sec-strigr e -?sec-val-ausentes);
Visualizar (Visualize): a visualização gráfica dos dados permite enxergar as informações com mais clareza, levantar novos questionamentos e até mesmo indicar se a pesquisa está no caminho correto ou não. Veremos mais sobre este assunto nos Capítulo 9, Capítulo 10 e Capítulo 11;
Modelar (Model): os modelos são usados para responder as perguntas norteadoras. Entra em cena a matemática, estatística e a computação como ferramentas para sua realização. Esta etapa não será aborada neste material, pois se tratar de um tema muito abrangente1.
Ainda, podemos destacar o termo Wrangling, que abrange as etapas de Limpar/Arrumar e Transformar. Traduzindo o termo, podemos entender que essas etapas são, literalmente, uma luta para que se consiga deixar os dados de forma mais concisa para serem analisados.
Por fim, vale destacar que as etapas de Transformar, Visualizar e Modelar são processos iterativos, ou seja, fazem parte de um processo de repetição cíclica de tarefas até que se alcance o resultado final da análise.
No capítulo seguinte, apresentaremos o software R e a IDE RStudio, desde a instalação, configuração e os primeiros passos a serem dados. Também vamos conhecer mais sobre o pacote tidyverse, que contém as principais funcionalidades a serem utilizadas em ciência de dados com R, detalhando os pacotes específicos para cada uma das etapas descritas anteriormente.
Para os interessados no assunto, recomendo o livro Tidy Modeling with R.↩︎
Para ter uma noção introdutória sobre este tópico, recomendo os capítulos 28 e 29 do livro R for Data Science.↩︎