7 Funções essenciais
7.1 Introdução
Neste capítulo, exploraremos as principais funções de manipulação de dados disponíveis no pacote dplyr.
O dplyr é um dos principais pacotes do tidyverse. Ele oferece um conjunto de ferramentas intuitivas e robustas para a manipulação de dados de forma eficiente. A seguir, apresentaremos as principais funções do pacote, que nos permitem resolver a maioria dos problemas relacionados à etapa de transformação dos dados.
Para os exemplos, utilizaremos um conjunto de dados da FAOSTAT. Os dados estão disponíveis para download clicando aqui.
Mas antes de adentrar ao pacote dplyr, vamos conhecer o operador pipe.
7.2 Operador pipe
Na maioria dos casos, utilizaremos mais de uma função para manipular os nossos dados. Com isso, entra em cena o pipe, cujo operador é |>.
A principal função do pipe é conectar linhas de códigos que se relacionam, executando-as em sequência e de uma só vez. Essa estrutura de código é chamada de pipeline.
Para ilustrá-lo, faremos uma mesma operação com e sem o pipe, calculando a média final das notas de um aluno, arredondada em uma casa decimal.
Com o pipe, colocamos as funções de acordo com a ordem em que desejamos realizar as operações. No exemplo, primeiro declaramos o objeto que contém os valores a serem utilizados. Em seguida, calculamos a média das notas. E por fim, arrendondamos em uma casa decimal o valor obtido no cálculo da média.
Dessa maneira, ao utilizar o pipe, evitamos de escrever funções dentro de funções, obtendo um código mais legível, claro e compacto, principalmente quando trabalhamos com diversas funções. Além disso, facilita a manutenção do código, caso seja preciso realizar alterações ou consertar possíveis problemas.
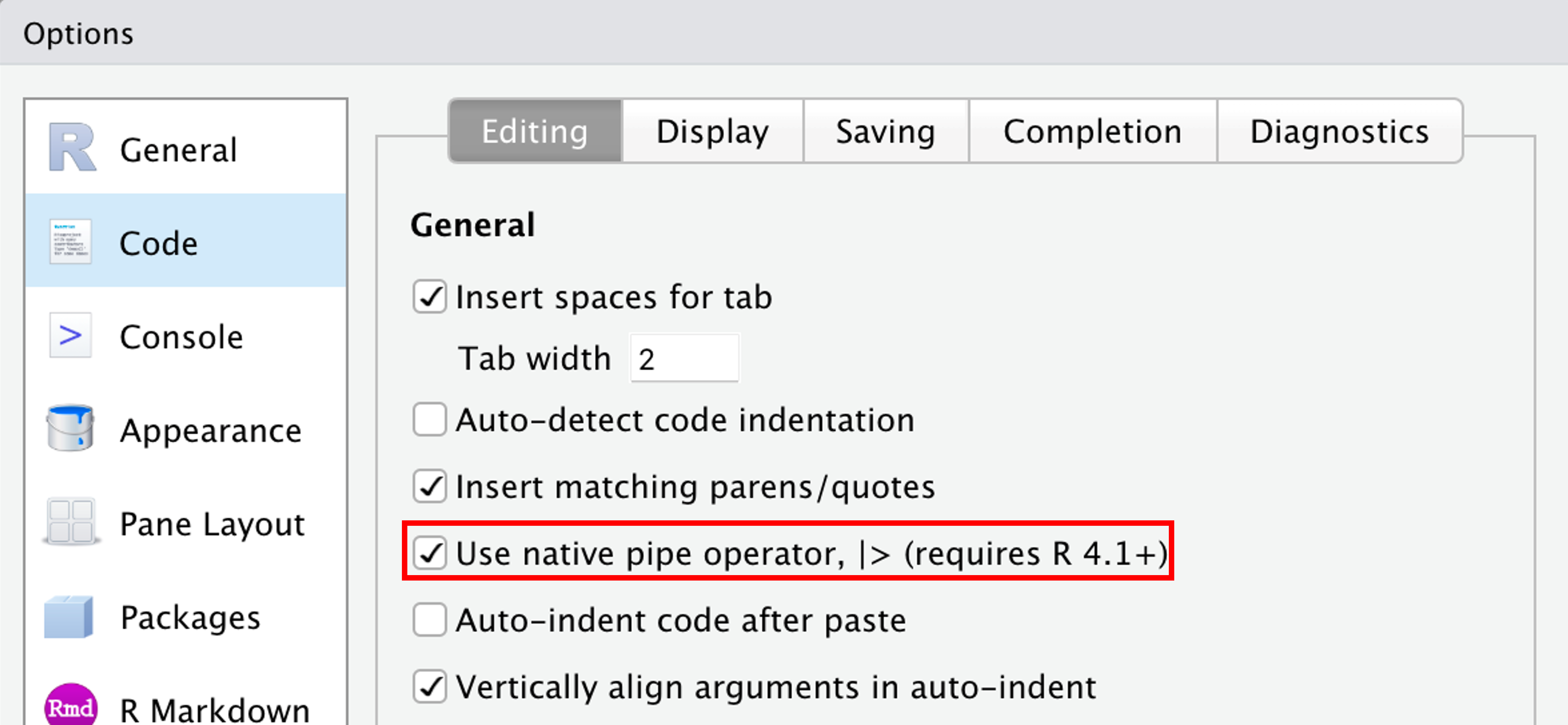
Podemos utilizar o atalho do teclado Ctrl + Shift + M (Cmd + Shift + M) para adicionar o pipe ao código. Para isso, devemos ativá-lo clicando na aba Tools do menu superior, seguido de Global Options.... Ao abrir a janela, em Code, habilite a opção indicada na Figura 7.1.
Os usuários mais antigos do R devem se lembrar que utilizávamos o operador %>% para o pipe. Este operador está presente no pacote magrittr, outro componente do tidyverse.
Apesar de ambos os operadores atuarem de modo semelhante para os casos mais simples, o |> funciona sem carregar o tidyverse, pois faz parte do pacote base do R, tornando-o mais simples e independente de qualquer pacote. Esta é a principal vantagem desse operador em relação ao do pacote magrittr.
Para entender mais sobre as mudanças entre os operadores, recomendo o seguinte texto: https://www.tidyverse.org/blog/2023/04/base-vs-magrittr-pipe/.
7.3 Colunas
Existem quatro principais funções relacionadas a manipulação de colunas (ou variáveis): select(), rename(), relocate() e mutate(). A seguir, trataremos de cada uma delas.
7.3.1 Selecionar
A primeira função que apresentaremos é a select(), que seleciona as variáveis de um data frame. Primeiramente, vamos importar e analisar os dados do arquivo prod_graos.csv.
graos <- readr::read_csv("dados/prod-graos.csv")
graos
#> # A tibble: 2,842 × 12
#> domain_code domain area_code_fao area item_code_fao item year_code year
#> <chr> <chr> <dbl> <chr> <dbl> <chr> <dbl> <dbl>
#> 1 QCL Crops an… 9 Arge… 56 Maize 1961 1961
#> 2 QCL Crops an… 9 Arge… 56 Maize 1962 1962
#> 3 QCL Crops an… 9 Arge… 56 Maize 1963 1963
#> 4 QCL Crops an… 9 Arge… 56 Maize 1964 1964
#> 5 QCL Crops an… 9 Arge… 56 Maize 1965 1965
#> 6 QCL Crops an… 9 Arge… 56 Maize 1966 1966
#> 7 QCL Crops an… 9 Arge… 56 Maize 1967 1967
#> 8 QCL Crops an… 9 Arge… 56 Maize 1968 1968
#> 9 QCL Crops an… 9 Arge… 56 Maize 1969 1969
#> 10 QCL Crops an… 9 Arge… 56 Maize 1970 1970
#> # ℹ 2,832 more rows
#> # ℹ 4 more variables: flag <chr>, flag_description <chr>, area_harvested <dbl>,
#> # production <dbl>
glimpse(graos)
#> Rows: 2,842
#> Columns: 12
#> $ domain_code <chr> "QCL", "QCL", "QCL", "QCL", "QCL", "QCL", "QCL", "QCL…
#> $ domain <chr> "Crops and livestock products", "Crops and livestock …
#> $ area_code_fao <dbl> 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,…
#> $ area <chr> "Argentina", "Argentina", "Argentina", "Argentina", "…
#> $ item_code_fao <dbl> 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 5…
#> $ item <chr> "Maize", "Maize", "Maize", "Maize", "Maize", "Maize",…
#> $ year_code <dbl> 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969,…
#> $ year <dbl> 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969,…
#> $ flag <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ flag_description <chr> "Official data", "Official data", "Official data", "O…
#> $ area_harvested <dbl> 2744400, 2756670, 2645400, 2970500, 3062300, 3274500,…
#> $ production <dbl> 4850000, 5220000, 4360000, 5350000, 5140000, 7040000,…O conjunto de dados traz a produção e área colhida de milho, soja, trigo e arroz nos países da América do Sul entre 1961 e 2019. Com a função glimpse(), constatamos que o data frame apresenta 2.842 observações e 12 variáveis. Como podemos observar, muitas das variáveis são códigos de identificação utilizados pelo sistema da FAO, os quais, neste momento, não nos interessam para a realização das análises.
As variáveis de interesse que iremos trabalhar são:
area: traz o nome dos 13 países da América do Sul;item: tipo de cultura - milho (maize), arroz (Rice, paddy), soja (Soybeans) e trigo (Wheat);year: ano da observação;area_harvested: traz os valores de área colhida em hectares;production: traz os valores de produção em toneladas.
Para selecionar as colunas de interesse, utilizamos a função select().
select(.data = graos, area, item, year, area_harvested, production)
#> # A tibble: 2,842 × 5
#> area item year area_harvested production
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 2,832 more rowsComo primeiro argumento, indicamos o objeto a ser manipulado e, em seguida, as colunas a serem selecionadas.
Utilizando o operador pipe, prosseguimos da seguinte maneira.
graos |> select(area, item, year, area_harvested, production)
#> # A tibble: 2,842 × 5
#> area item year area_harvested production
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 2,832 more rowsPrimeiro, declaramos qual o conjunto de dados iremos utilizar, seguido da função select() com as colunas que desejamos selecionar.
Podemos selecionar várias colunas consecutivas com o operador :. Basta informar os nomes ou as posições da primeira e da última coluna que se deseja selecionar.
graos |> select(area:year)
#> # A tibble: 2,842 × 5
#> area item_code_fao item year_code year
#> <chr> <dbl> <chr> <dbl> <dbl>
#> 1 Argentina 56 Maize 1961 1961
#> 2 Argentina 56 Maize 1962 1962
#> 3 Argentina 56 Maize 1963 1963
#> 4 Argentina 56 Maize 1964 1964
#> 5 Argentina 56 Maize 1965 1965
#> 6 Argentina 56 Maize 1966 1966
#> 7 Argentina 56 Maize 1967 1967
#> 8 Argentina 56 Maize 1968 1968
#> 9 Argentina 56 Maize 1969 1969
#> 10 Argentina 56 Maize 1970 1970
#> # ℹ 2,832 more rows
graos |> select(4:8)
#> # A tibble: 2,842 × 5
#> area item_code_fao item year_code year
#> <chr> <dbl> <chr> <dbl> <dbl>
#> 1 Argentina 56 Maize 1961 1961
#> 2 Argentina 56 Maize 1962 1962
#> 3 Argentina 56 Maize 1963 1963
#> 4 Argentina 56 Maize 1964 1964
#> 5 Argentina 56 Maize 1965 1965
#> 6 Argentina 56 Maize 1966 1966
#> 7 Argentina 56 Maize 1967 1967
#> 8 Argentina 56 Maize 1968 1968
#> 9 Argentina 56 Maize 1969 1969
#> 10 Argentina 56 Maize 1970 1970
#> # ℹ 2,832 more rowsEm conjunto com a select(), podemos utilizar outras funções que nos auxiliam na seleção de colunas.
-
where(): seleciona as colunas que possuem determinada classe.
graos |> select(where(is.numeric))
#> # A tibble: 2,842 × 6
#> area_code_fao item_code_fao year_code year area_harvested production
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 9 56 1961 1961 2744400 4850000
#> 2 9 56 1962 1962 2756670 5220000
#> 3 9 56 1963 1963 2645400 4360000
#> 4 9 56 1964 1964 2970500 5350000
#> 5 9 56 1965 1965 3062300 5140000
#> 6 9 56 1966 1966 3274500 7040000
#> 7 9 56 1967 1967 3450500 8510000
#> 8 9 56 1968 1968 3377700 6560000
#> 9 9 56 1969 1969 3556000 6860000
#> 10 9 56 1970 1970 4017330 9360000
#> # ℹ 2,832 more rows-
starts_with(): seleciona colunas que começam com um texto padrão.
graos |> select(starts_with("year"))
#> # A tibble: 2,842 × 2
#> year_code year
#> <dbl> <dbl>
#> 1 1961 1961
#> 2 1962 1962
#> 3 1963 1963
#> 4 1964 1964
#> 5 1965 1965
#> 6 1966 1966
#> 7 1967 1967
#> 8 1968 1968
#> 9 1969 1969
#> 10 1970 1970
#> # ℹ 2,832 more rows-
ends_with(): seleciona colunas que terminam com um texto padrão.
-
contains(): seleciona colunas que possuem um texto padrão.
graos |> select(contains("code"))
#> # A tibble: 2,842 × 4
#> domain_code area_code_fao item_code_fao year_code
#> <chr> <dbl> <dbl> <dbl>
#> 1 QCL 9 56 1961
#> 2 QCL 9 56 1962
#> 3 QCL 9 56 1963
#> 4 QCL 9 56 1964
#> 5 QCL 9 56 1965
#> 6 QCL 9 56 1966
#> 7 QCL 9 56 1967
#> 8 QCL 9 56 1968
#> 9 QCL 9 56 1969
#> 10 QCL 9 56 1970
#> # ℹ 2,832 more rowsTambém podemos retirar colunas inserindo o operador - antes do nome da variável ou das funções auxiliares.
graos |> select(-contains("code"), -contains("flag"), -domain)
#> # A tibble: 2,842 × 5
#> area item year area_harvested production
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 2,832 more rowsCom a função select(), também podemos renomear as variáveis selecionadas. Como primeiro argumento, inserimos o novo nome, seguido do sinal de = e o nome original da variável.
graos |>
select(
pais = area,
cultura = item,
ano = year,
colheita = area_harvested,
producao = production
)
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 2,832 more rows7.3.2 Renomear
Para apenas renomear alguma variável, sem realizar a seleção dessas, utilizamos a função rename().
graos |>
rename(
pais = area,
cultura = item,
ano = year,
colheita = area_harvested,
producao = production
) |>
glimpse()
#> Rows: 2,842
#> Columns: 12
#> $ domain_code <chr> "QCL", "QCL", "QCL", "QCL", "QCL", "QCL", "QCL", "QCL…
#> $ domain <chr> "Crops and livestock products", "Crops and livestock …
#> $ area_code_fao <dbl> 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,…
#> $ pais <chr> "Argentina", "Argentina", "Argentina", "Argentina", "…
#> $ item_code_fao <dbl> 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 5…
#> $ cultura <chr> "Maize", "Maize", "Maize", "Maize", "Maize", "Maize",…
#> $ year_code <dbl> 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969,…
#> $ ano <dbl> 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969,…
#> $ flag <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ flag_description <chr> "Official data", "Official data", "Official data", "O…
#> $ colheita <dbl> 2744400, 2756670, 2645400, 2970500, 3062300, 3274500,…
#> $ producao <dbl> 4850000, 5220000, 4360000, 5350000, 5140000, 7040000,…Podemos utilizar as funções select() e rename() de forma integrada.
graos_selecionado <- graos |>
select(area, item, year, area_harvested, production) |>
rename(
pais = area,
cultura = item,
ano = year,
colheita = area_harvested,
producao = production
)
graos_selecionado
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 2,832 more rowsNote que salvamos as alterações realizadas no objeto graos_selecionado. A seguir, utilizaremos este objeto para os demais exemplos.
7.3.3 Realocar
Utilizamos a função relocate() para mover as colunas de lugar.
graos_selecionado |> relocate(ano, pais, cultura, producao, colheita)
#> # A tibble: 2,842 × 5
#> ano pais cultura producao colheita
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1961 Argentina Maize 4850000 2744400
#> 2 1962 Argentina Maize 5220000 2756670
#> 3 1963 Argentina Maize 4360000 2645400
#> 4 1964 Argentina Maize 5350000 2970500
#> 5 1965 Argentina Maize 5140000 3062300
#> 6 1966 Argentina Maize 7040000 3274500
#> 7 1967 Argentina Maize 8510000 3450500
#> 8 1968 Argentina Maize 6560000 3377700
#> 9 1969 Argentina Maize 6860000 3556000
#> 10 1970 Argentina Maize 9360000 4017330
#> # ℹ 2,832 more rowsÉ possível selecionar apenas algumas colunas (não necessariamente todas as variáveis do conjunto de dados) para serem arranjadas. Por padrão, as variáveis escolhidas são realocadas para o início do conjunto de dados.
graos_selecionado |> relocate(ano, pais)
#> # A tibble: 2,842 × 5
#> ano pais cultura colheita producao
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1961 Argentina Maize 2744400 4850000
#> 2 1962 Argentina Maize 2756670 5220000
#> 3 1963 Argentina Maize 2645400 4360000
#> 4 1964 Argentina Maize 2970500 5350000
#> 5 1965 Argentina Maize 3062300 5140000
#> 6 1966 Argentina Maize 3274500 7040000
#> 7 1967 Argentina Maize 3450500 8510000
#> 8 1968 Argentina Maize 3377700 6560000
#> 9 1969 Argentina Maize 3556000 6860000
#> 10 1970 Argentina Maize 4017330 9360000
#> # ℹ 2,832 more rowsPodemos especificar para onde as colunas serão movidas com os argumentos .before = e .after = (antes ou depois de determinada coluna, respectivamente).
graos_selecionado |> relocate(ano, cultura, .before = pais)
#> # A tibble: 2,842 × 5
#> ano cultura pais colheita producao
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1961 Maize Argentina 2744400 4850000
#> 2 1962 Maize Argentina 2756670 5220000
#> 3 1963 Maize Argentina 2645400 4360000
#> 4 1964 Maize Argentina 2970500 5350000
#> 5 1965 Maize Argentina 3062300 5140000
#> 6 1966 Maize Argentina 3274500 7040000
#> 7 1967 Maize Argentina 3450500 8510000
#> 8 1968 Maize Argentina 3377700 6560000
#> 9 1969 Maize Argentina 3556000 6860000
#> 10 1970 Maize Argentina 4017330 9360000
#> # ℹ 2,832 more rows
graos_selecionado |> relocate(ano, cultura, .after = pais)
#> # A tibble: 2,842 × 5
#> pais ano cultura colheita producao
#> <chr> <dbl> <chr> <dbl> <dbl>
#> 1 Argentina 1961 Maize 2744400 4850000
#> 2 Argentina 1962 Maize 2756670 5220000
#> 3 Argentina 1963 Maize 2645400 4360000
#> 4 Argentina 1964 Maize 2970500 5350000
#> 5 Argentina 1965 Maize 3062300 5140000
#> 6 Argentina 1966 Maize 3274500 7040000
#> 7 Argentina 1967 Maize 3450500 8510000
#> 8 Argentina 1968 Maize 3377700 6560000
#> 9 Argentina 1969 Maize 3556000 6860000
#> 10 Argentina 1970 Maize 4017330 9360000
#> # ℹ 2,832 more rows7.3.4 Modificar e criar
Para modificar ou criar novas variáveis, utilizamos a função mutate().
graos_selecionado |> mutate(producao = producao * 1000)
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000000
#> 2 Argentina Maize 1962 2756670 5220000000
#> 3 Argentina Maize 1963 2645400 4360000000
#> 4 Argentina Maize 1964 2970500 5350000000
#> 5 Argentina Maize 1965 3062300 5140000000
#> 6 Argentina Maize 1966 3274500 7040000000
#> 7 Argentina Maize 1967 3450500 8510000000
#> 8 Argentina Maize 1968 3377700 6560000000
#> 9 Argentina Maize 1969 3556000 6860000000
#> 10 Argentina Maize 1970 4017330 9360000000
#> # ℹ 2,832 more rowsNo exemplo anterior, transformamos os valores da coluna producao, em toneladas, para quilogramas. Contudo, também podemos manter a coluna original e criar uma nova. Basta designar um novo nome à nova variável.
graos_selecionado |> mutate(producao_kg = producao * 1000)
#> # A tibble: 2,842 × 6
#> pais cultura ano colheita producao producao_kg
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000 4850000000
#> 2 Argentina Maize 1962 2756670 5220000 5220000000
#> 3 Argentina Maize 1963 2645400 4360000 4360000000
#> 4 Argentina Maize 1964 2970500 5350000 5350000000
#> 5 Argentina Maize 1965 3062300 5140000 5140000000
#> 6 Argentina Maize 1966 3274500 7040000 7040000000
#> 7 Argentina Maize 1967 3450500 8510000 8510000000
#> 8 Argentina Maize 1968 3377700 6560000 6560000000
#> 9 Argentina Maize 1969 3556000 6860000 6860000000
#> 10 Argentina Maize 1970 4017330 9360000 9360000000
#> # ℹ 2,832 more rows7.4 Linhas
Para realizar manipulações de linhas (ou observações) de um conjunto de dados, utilizamos três principais funções: filter(), arrange() e distinct(). Discutiremos sobre cada uma a seguir.
7.4.1 Filtrar
Na Seção 3.8, tratamos sobre a lógica por trás da operação de filtragem. Nesta seção, apresentaremos a função filter(), que permite filtrar valores específicos em um conjunto de dados de forma simples e eficiente, utilizando operações lógicas para refinar a busca e extrair apenas as observações desejadas.
graos_selecionado |> filter(pais == "Chile")
#> # A tibble: 233 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Chile Maize 1961 83330 162810
#> 2 Chile Maize 1962 84560 180760
#> 3 Chile Maize 1963 84350 176020
#> 4 Chile Maize 1964 88160 241520
#> 5 Chile Maize 1965 87644 260000
#> 6 Chile Maize 1966 80700 285327
#> 7 Chile Maize 1967 92200 362200
#> 8 Chile Maize 1968 88540 320810
#> 9 Chile Maize 1969 58440 153792
#> 10 Chile Maize 1970 73860 239052
#> # ℹ 223 more rowsNo exemplo anterior, filtramos apenas as observações referentes ao país Chile, contidas na coluna pais. Para isso, aplicamos a condição lógica ==, solicitando que sejam retornadas apenas as linhas em que o valor da coluna pais seja exatamente igual a Chile.
As demais condições lógicas apresentadas na Tabela 3.2 são aplicáveis na função filter().
Também podemos combinar diferentes condições lógicas sobre diferentes variáveis.
graos_selecionado |>
filter(
pais %in% c("Brazil", "Argentina", "Chile"),
ano == 2010
)
#> # A tibble: 12 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 2010 2904035 22663095
#> 2 Argentina Rice, paddy 2010 215670 1243259
#> 3 Argentina Soybeans 2010 18130800 52675464
#> 4 Argentina Wheat 2010 3325457 9016373
#> 5 Brazil Maize 2010 12678875 55364271
#> 6 Brazil Rice, paddy 2010 2722459 11235986
#> 7 Brazil Soybeans 2010 23327296 68756343
#> 8 Brazil Wheat 2010 2181567 6171250
#> 9 Chile Maize 2010 122547 1357921
#> 10 Chile Rice, paddy 2010 24527 94673
#> 11 Chile Soybeans 2010 NA NA
#> 12 Chile Wheat 2010 264304 1523921No código anterior, com o operador %in%, filtramos apenas as observações em que a coluna pais contém um dos três valores: "Brazil", "Argentina" ou "Chile" e, de forma simultânea, também filtramos apenas as observações em que a coluna ano tem o valor 2010. Essa operação é equivalente a fazer o seguinte comando.
graos_selecionado |>
filter(pais %in% c("Brazil", "Argentina", "Chile") & ano == 2010)
#> # A tibble: 12 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 2010 2904035 22663095
#> 2 Argentina Rice, paddy 2010 215670 1243259
#> 3 Argentina Soybeans 2010 18130800 52675464
#> 4 Argentina Wheat 2010 3325457 9016373
#> 5 Brazil Maize 2010 12678875 55364271
#> 6 Brazil Rice, paddy 2010 2722459 11235986
#> 7 Brazil Soybeans 2010 23327296 68756343
#> 8 Brazil Wheat 2010 2181567 6171250
#> 9 Chile Maize 2010 122547 1357921
#> 10 Chile Rice, paddy 2010 24527 94673
#> 11 Chile Soybeans 2010 NA NA
#> 12 Chile Wheat 2010 264304 1523921Com o operador & (“E” lógico), combinamos condições que devem ser todas verdadeiras ao mesmo tempo, ou seja, uma linha só será filtrada se todas as condições apresentadas forem atendidas simultaneamente. No exemplo, filtra-se somente as linhas em que a coluna pais contém os valores "Brazil", "Argentina" ou "Chile" E a coluna ano é 2010.
Por outro lado, o operador | (“OU” lógico) é usado para combinar condições onde basta que apenas uma delas seja verdadeira, ou seja, uma linha será selecionada se pelo menos uma das condições for atendida (uma condição OU a outra condição).
graos_selecionado |> filter(cultura == "Maize" | ano == 2010)
#> # A tibble: 816 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 806 more rowsPor fim, podemos excluir determinadas observações com o operador !.
graos_selecionado |> filter(!(ano %in% 1962:2018))
#> # A tibble: 94 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 2019 7232761 56860704
#> 3 Argentina Rice, paddy 1961 46000 149000
#> 4 Argentina Rice, paddy 2019 183285 1189866
#> 5 Argentina Soybeans 1961 980 957
#> 6 Argentina Soybeans 2019 16575887 55263891
#> 7 Argentina Wheat 1961 4420900 5725000
#> 8 Argentina Wheat 2019 6050953 19459727
#> 9 Bolivia (Plurinational State of) Maize 1961 207030 258800
#> 10 Bolivia (Plurinational State of) Maize 2019 468080 987503
#> # ℹ 84 more rowsNo exemplo anterior, excluímos todas as observações contidas entre os anos de 1962 e 2018.
7.4.2 Ordenar
Com a função arrange(), podemos ordenar as linhas de acordo com alguma variável.
graos_selecionado |> arrange(producao)
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Chile Soybeans 1990 0 0
#> 2 Chile Soybeans 1991 0 0
#> 3 Chile Soybeans 1992 0 0
#> 4 Chile Soybeans 1988 NA 0
#> 5 French Guyana Maize 1990 0 0
#> 6 French Guyana Soybeans 1990 0 0
#> 7 French Guyana Soybeans 1991 0 0
#> 8 French Guyana Soybeans 1992 0 0
#> 9 Guyana Soybeans 1990 0 0
#> 10 Guyana Soybeans 1991 0 0
#> # ℹ 2,832 more rowsPor padrão, a função arrange() ordena os valores em ordem crescente. Para ordená-las em ordem decrescente, utilizamos a função desc() dentro da função arrange().
graos_selecionado |> arrange(desc(producao))
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Brazil Soybeans 2018 34777936 117912450
#> 2 Brazil Soybeans 2017 33959879 114732101
#> 3 Brazil Soybeans 2019 35881447 114269392
#> 4 Brazil Maize 2019 17518054 101138617
#> 5 Brazil Maize 2017 17427206 97910658
#> 6 Brazil Soybeans 2015 32181243 97464936
#> 7 Brazil Soybeans 2016 33183119 96394820
#> 8 Brazil Soybeans 2014 30273763 86760520
#> 9 Brazil Maize 2015 15407143 85283074
#> 10 Brazil Maize 2018 16126368 82366531
#> # ℹ 2,832 more rowsAlém disso, podemos ordenar as observações com base em duas ou mais variáveis, sejam elas quantitativas ou qualitativas.
graos_selecionado |> arrange(pais, producao)
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Soybeans 1961 980 957
#> 2 Argentina Soybeans 1962 9649 11220
#> 3 Argentina Soybeans 1964 12220 14000
#> 4 Argentina Soybeans 1965 16422 17000
#> 5 Argentina Soybeans 1966 15689 18200
#> 6 Argentina Soybeans 1963 19302 18920
#> 7 Argentina Soybeans 1967 17290 20500
#> 8 Argentina Soybeans 1968 20200 22000
#> 9 Argentina Soybeans 1970 25970 26800
#> 10 Argentina Soybeans 1969 28200 31800
#> # ℹ 2,832 more rows
graos_selecionado |> arrange(producao, pais)
#> # A tibble: 2,842 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Chile Soybeans 1990 0 0
#> 2 Chile Soybeans 1991 0 0
#> 3 Chile Soybeans 1992 0 0
#> 4 Chile Soybeans 1988 NA 0
#> 5 French Guyana Maize 1990 0 0
#> 6 French Guyana Soybeans 1990 0 0
#> 7 French Guyana Soybeans 1991 0 0
#> 8 French Guyana Soybeans 1992 0 0
#> 9 Guyana Soybeans 1990 0 0
#> 10 Guyana Soybeans 1991 0 0
#> # ℹ 2,832 more rowsPerceba que a ordem de declaração das variáveis na função arrange() altera a prioridade da ordenação. No exemplo anterior, primeiro, organizamos os nomes dos países por ordem alfabética para depois ordenar pelos valores de produção. No outro caso, começamos a ordenar os valores de produção para depois organizar, alfabeticamente, os nomes dos países, tendo assim um resultado distinto do exemplo anterior.
7.4.3 Distinguir
A função distinct() é utilizada para remover observações duplicadas. Veja o exmeplo a seguir.
dados <- tibble(
pais = c("Brasil", "Brasil", "Argentina", "Argentina", "Chile"),
ano = c(2020, 2021, 2021, 2021, 2020),
producao_cevada = c(50, 60, 110, 110, 85)
)
dados
#> # A tibble: 5 × 3
#> pais ano producao_cevada
#> <chr> <dbl> <dbl>
#> 1 Brasil 2020 50
#> 2 Brasil 2021 60
#> 3 Argentina 2021 110
#> 4 Argentina 2021 110
#> 5 Chile 2020 85No data frame dados, há uma observação duplicada referente à produção de cevada na Argentina no ano de 2021.
dados |> distinct()
#> # A tibble: 4 × 3
#> pais ano producao_cevada
#> <chr> <dbl> <dbl>
#> 1 Brasil 2020 50
#> 2 Brasil 2021 60
#> 3 Argentina 2021 110
#> 4 Chile 2020 85Com a função distinct(), removemos a linha duplicada. Ou seja, ela verifica todas as colunas e exclui as linhas que são idênticas em todas as colunas.
Também podemos aplicar a função para determinadas colunas.
dados |> distinct(pais)
#> # A tibble: 3 × 1
#> pais
#> <chr>
#> 1 Brasil
#> 2 Argentina
#> 3 ChileEsse comando mantém apenas as observações exclusivas da coluna pais, descartando todas as outras informações associadas.
Para manter as outras colunas ao filtrar por linhas exclusivas, podemos usar o argumento .keep_all = TRUE.
dados |> distinct(pais, .keep_all = TRUE)
#> # A tibble: 3 × 3
#> pais ano producao_cevada
#> <chr> <dbl> <dbl>
#> 1 Brasil 2020 50
#> 2 Argentina 2021 110
#> 3 Chile 2020 85Com isso, mantém-se apenas uma linha para cada valor único na coluna pais, ignorando as demais colunas. Com isso, o R seleciona a primeira ocorrência de cada valor único de pais, e as outras colunas (como ano e producao_milho) são mantidas com os valores correspondentes à primeira linha de cada país.
7.5 Grupos
O pacote dplyr possui funções que nos permite trabalhar com grupos de variáveis. Nesta seção, abordaremos as seguintes funções: summarise(), group_by() e a família de funções slice_().
7.5.1 summarise() e group_by()
A função summarise() calcula medidas-resumo de variáveis quantitativas. Ela resume os dados de determinada observação exclusiva de acordo com uma medida de interesse, como a média, mediana, frequência, proporção, dentre outras.
graos_selecionado |>
summarise(
media_producao = mean(producao, na.rm = TRUE),
media_colheita = mean(colheita, na.rm = TRUE),
max_producao = max(producao, na.rm = TRUE),
max_colheita = max(colheita, na.rm = TRUE)
)
#> # A tibble: 1 × 4
#> media_producao media_colheita max_producao max_colheita
#> <dbl> <dbl> <dbl> <dbl>
#> 1 3130662. 1185376. 117912450 35881447O argumento na.rm = TRUE ignora os valores NA para o cálculo da média e produção máxima. Trataremos com mais detalhes sobre esse assunto no ?sec-val-ausentes.
Para calcular medidas agrupadas de acordo com mais de uma variável, utilizamos a função group_by()1. No exemplo abaixo, agruparemos a variável pais para calcular a média e o valor máximo de produção (production) e de área colhida (area harvested) por país.
graos_selecionado |>
group_by(pais) |>
summarise(
media_producao = mean(producao, na.rm = TRUE),
media_colheita = mean(colheita, na.rm = TRUE),
max_producao = max(producao, na.rm = TRUE),
max_colheita = max(colheita, na.rm = TRUE)
)
#> # A tibble: 13 × 5
#> pais media_producao media_colheita max_producao max_colheita
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Argentina 11069997. 3889868. 61446556 19504648
#> 2 Bolivia (Plurination… 445249. 243134. 3203992 1387973
#> 3 Brazil 19638343. 7735115. 117912450 35881447
#> 4 Chile 637716. 179720. 1921652 779966
#> 5 Colombia 753641. 280305. 3292983 868867
#> 6 Ecuador 377982. 168084. 1873525 577784
#> 7 French Guyana 5780. 1885. 31544 9281
#> 8 Guyana 182259. 54487. 1050000 206428
#> 9 Paraguay 1134512. 444338. 11045971 3565000
#> 10 Peru 625835. 190828. 3557900 514945
#> 11 Suriname 67796. 17442. 301971 75136
#> 12 Uruguay 479607. 184556. 3212000 1334000
#> 13 Venezuela (Bolivaria… 493956. 183419. 2638010 791545Também podemos agrupar a partir de duas ou mais variáveis. A seguir, agruparemos as colunas pais e cultura para calcular a média e o máximo da produção e da área colhida por país e por tipo de cultura.
graos_selecionado |>
group_by(pais, cultura) |>
summarise(
media_producao = mean(producao, na.rm = TRUE),
media_colheita = mean(colheita, na.rm = TRUE),
max_producao = max(producao, na.rm = TRUE),
max_colheita = max(colheita, na.rm = TRUE)
)
#> # A tibble: 49 × 6
#> # Groups: pais [13]
#> pais cultura media_producao media_colheita max_producao max_colheita
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 14812880. 3243095. 56860704 7232761
#> 2 Argentina Rice, … 714791. 135827. 1748075 289200
#> 3 Argentina Soybea… 17941231. 6967484. 61446556 19504648
#> 4 Argentina Wheat 10811085. 5213066. 19459727 7364200
#> 5 Bolivia (Plu… Maize 552919. 297456. 1260926 468080
#> 6 Bolivia (Plu… Rice, … 234899. 108135. 600044 194237
#> 7 Bolivia (Plu… Soybea… 922200. 472537. 3203992 1387973
#> 8 Bolivia (Plu… Wheat 111395. 117736. 337599 229822
#> 9 Brazil Maize 33776948. 12033678. 101138617 17518054
#> 10 Brazil Rice, … 9467493. 4056617. 13476994 6656480
#> # ℹ 39 more rows
7.5.2 Funções slice_()
A família de funções slice_() permite extrair observações baseada em sua posição no data frame.
-
slice_head(): seleciona as n primeiras linhas.
graos_selecionado |> slice_head(n = 2)
#> # A tibble: 2 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000Também podemos utilizar proporções de linhas com o argumento prop =, cujo valor varia de 0 a 1.
graos_selecionado |> slice_head(prop = 0.01)
#> # A tibble: 28 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Argentina Maize 1961 2744400 4850000
#> 2 Argentina Maize 1962 2756670 5220000
#> 3 Argentina Maize 1963 2645400 4360000
#> 4 Argentina Maize 1964 2970500 5350000
#> 5 Argentina Maize 1965 3062300 5140000
#> 6 Argentina Maize 1966 3274500 7040000
#> 7 Argentina Maize 1967 3450500 8510000
#> 8 Argentina Maize 1968 3377700 6560000
#> 9 Argentina Maize 1969 3556000 6860000
#> 10 Argentina Maize 1970 4017330 9360000
#> # ℹ 18 more rowsNo exemplo anterior, selecionamos 1% (prop = 0.01) das primeiras linhas do conjunto de dados.
-
slice_tail(): seleciona as n últimas linhas.
graos_selecionado |> slice_tail(n = 2)
#> # A tibble: 2 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Venezuela (Bolivarian Republic of) Wheat 2009 NA 143
#> 2 Venezuela (Bolivarian Republic of) Wheat 2010 NA 183Ou ainda, seleciona p% das últimas linhas do conjunto de dados.
graos_selecionado |> slice_tail(prop = 0.01)
#> # A tibble: 28 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Venezuela (Bolivarian Republic of) Wheat 2009 48 NA
#> 2 Venezuela (Bolivarian Republic of) Wheat 2010 61 NA
#> 3 Venezuela (Bolivarian Republic of) Wheat 2011 68 204
#> 4 Venezuela (Bolivarian Republic of) Wheat 2012 73 218
#> 5 Venezuela (Bolivarian Republic of) Wheat 2013 54 161
#> 6 Venezuela (Bolivarian Republic of) Wheat 2014 54 161
#> 7 Venezuela (Bolivarian Republic of) Wheat 2015 60 179
#> 8 Venezuela (Bolivarian Republic of) Wheat 2016 47 140
#> 9 Venezuela (Bolivarian Republic of) Wheat 2017 209 584
#> 10 Venezuela (Bolivarian Republic of) Wheat 2018 431 1151
#> # ℹ 18 more rows-
slice_min(): seleciona a linha com o menor valor de determinada variável.
graos_selecionado |> slice_min(order_by = producao)
#> # A tibble: 11 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Chile Soybeans 1990 0 0
#> 2 Chile Soybeans 1991 0 0
#> 3 Chile Soybeans 1992 0 0
#> 4 Chile Soybeans 1988 NA 0
#> 5 French Guyana Maize 1990 0 0
#> 6 French Guyana Soybeans 1990 0 0
#> 7 French Guyana Soybeans 1991 0 0
#> 8 French Guyana Soybeans 1992 0 0
#> 9 Guyana Soybeans 1990 0 0
#> 10 Guyana Soybeans 1991 0 0
#> 11 Guyana Soybeans 1992 0 0Note que a função nos retorna todas as linhas com o menor valor de produção, no caso, o valor zero. Caso queira selecionar n linhas e não todas as linhas com menor valor de determinada variável, devemos declarar a quantidade de linhas em n = junto ao argumento with_ties = FALSE.
graos_selecionado |> slice_min(order_by = producao, n = 5, with_ties = FALSE)
#> # A tibble: 5 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Chile Soybeans 1990 0 0
#> 2 Chile Soybeans 1991 0 0
#> 3 Chile Soybeans 1992 0 0
#> 4 Chile Soybeans 1988 NA 0
#> 5 French Guyana Maize 1990 0 0-
slice_max(): seleciona a linha com o maior valor de determinada variável.
graos_selecionado |> slice_max(order_by = producao)
#> # A tibble: 1 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Brazil Soybeans 2018 34777936 117912450De forma semelhante apresentada para a slice_min(), podemos selecionar as n linhas com maior valor de certa variável.
graos_selecionado |> slice_max(order_by = producao, n = 5)
#> # A tibble: 5 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Brazil Soybeans 2018 34777936 117912450
#> 2 Brazil Soybeans 2017 33959879 114732101
#> 3 Brazil Soybeans 2019 35881447 114269392
#> 4 Brazil Maize 2019 17518054 101138617
#> 5 Brazil Maize 2017 17427206 97910658-
slice_sample(): seleciona n linhas de forma aleatória.
graos_selecionado |> slice_sample(n = 5)
#> # A tibble: 5 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Brazil Wheat 1997 1521545 2489070
#> 2 Brazil Soybeans 1973 3615058 5011614
#> 3 Colombia Maize 1990 836900 1213300
#> 4 Guyana Rice, paddy 1975 134000 292000
#> 5 Venezuela (Bolivarian Republic of) Wheat 1966 2854 1427
graos_selecionado |> slice_sample(n = 5)
#> # A tibble: 5 × 5
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Ecuador Soybeans 1962 65 80
#> 2 Chile Maize 1970 73860 239052
#> 3 Chile Rice, paddy 1976 28590 97640
#> 4 Suriname Rice, paddy 1974 44353 162417
#> 5 Brazil Wheat 1969 1407115 1373691Por fim, podemos selecionar uma certa quantidade de observações de acordo com determinado agrupamento de variáveis. Para isso, utilizamos a função group_by().
graos_selecionado |>
group_by(cultura) |>
slice_max(producao)
#> # A tibble: 4 × 5
#> # Groups: cultura [4]
#> pais cultura ano colheita producao
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Brazil Maize 2019 17518054 101138617
#> 2 Brazil Rice, paddy 2011 2752891 13476994
#> 3 Brazil Soybeans 2018 34777936 117912450
#> 4 Argentina Wheat 2019 6050953 19459727No exemplo anterior, selecionamos as linhas com maior produção de acordo com o tipo de cultura.
7.6 Resumo
Neste capítulo, apresentamos as principais ferramentas do pacote dplyr para a manipulação e transformação de data frames. Grande parte dos desafios dessa etapa na ciência de dados podem ser resolvidos com as funções abordadas até aqui. Dessa forma, é essencial que o leitor dedique um tempo significativo para estudá-las e compreender seu funcionamento em diferentes contextos.
A seguir, apresentaremos funções que permitem combinar múltiplos conjuntos de dados relacionados: as famílias de funções bind_(), que unem dados de forma simples, e _join(), que realizam junções mais estruturadas com base em colunas comuns.
A versão mais recente do pacote
dplyr(dplyr 1.1.0) traz uma nova possibilidade para agrupar variáveis, a.by/by. Essa novidade atua de modo análogo à funçãogroup_by(), porém com uma sintaxe de código diferente. Para saber mais, acesse: https://www.tidyverse.org/blog/2023/02/dplyr-1-1-0-per-operation-grouping/.↩︎