Capítulo2 Ciência de dados e R
Aviso: Para ler a versão mais recente deste material, acesse: https://gustavojy.github.io/apostila-icdr/
2.1 O que é Ciência de Dados?
A ciência de dados, como o próprio termo sugere, consiste no estudo e análise de dados, com o objetivo de extrair informações relevantes, utilizando técnicas e conhecimentos multidisciplinares. Por mais que o termo tenha se popularizado fortemente nos últimos anos devido à massiva geração de dados em elevadas quantidades, diversidades e velocidades, sua concepção se origina no século passado, seja por nomes notáveis como o do matemático e estatístico John W. Tukey, mas também por aqueles que atuavam nas áreas de negócios e de pesquisa que, sem a pretensão de nomear ou organizar uma nova área do conhecimento, poderiam ser considerados cientistas de dados.
A concepção recente de ciência de dados abrange pelo menos três grandes áreas do conhecimento, podendo ser descrita por um diagrama de Venn, idealizado em 2010, por Drew Conway:
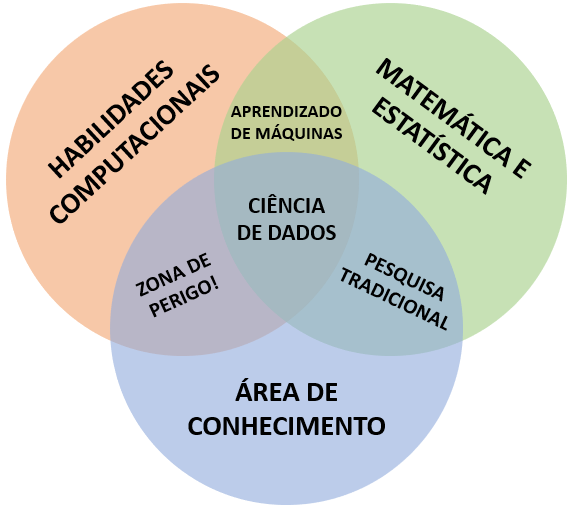
Figure 2.1: Diagrama de Venn da ciência de dados.
O diagrama é composto pelo conjunto de habilidades computacionais, conhecimento de matemática e estatística e domínio da área de conhecimento. Assim, as intersecções entre os conjuntos resultam em certas habilidades, descritas da seguinte maneira:
Aprendizado de máquinas: do termo em inglês machine learning, consiste na intersecção entre as habilidades computacionais e de matemática e estatística. Utiliza estas bases para entender os modelos utilizados e detectar os padrões que serão replicados, a partir dos artifícios da programação, com o intuito de colocar em prática os algoritmos.
Pesquisa tradicional: é a intersecção entre as áreas da matemática e estatística e área de conhecimento. Consiste na aplicação das bases matemáticas e estatísticas para solucionar problemas de uma área de atuação específica, sendo uma prática comum e tradicional no meio da pesquisa, principalmente acadêmica.
Zona de perigo: a intersecção entre habilidades computacionais e área de conhecimento resulta em uma chamada zona de perigo, pois quem se encontra nesta situação consegue resolver problemas aplicando algoritmos, porém sem ter bases teóricas para compreender ou averiguar os resultados.
Ciência de dados: a ciência de dados é o resultado da intersecção entre as três áreas - habilidades computacionais, matemática e estatística e área de conhecimento. Em teoria, um cientista de dados não possui total domínio destas três áreas, ou senão, possui especialização em alguma das três, contudo sabe aplicá-las para resolver problemas.
Tendo em vista as bases que definem um cientista de dados, entraremos no âmbito da programação, conhecendo um pouco mais sobre o software R.
2.2 R / RStudio
O R é uma das linguagens de programação mais utilizadas por cientistas de dados. Foi desenvolvido por Ross Ihaka e Robert Gentleman, na Universidade de Auckland, Nova Zelândia, em 1993. Iniciou como uma linguagem focada em programação estatística, mas que, ao longo do tempo, tornou-se cada vez mais encorpada e diversificada. Atualmente, o R Development Core Team atua na manutenção e no desenvolvimento da linguagem, sendo composto por diversos membros, dentre eles, seus idealizadores.
Por ser um software gratuito de código aberto (Open source), possibilitou a formação de uma comunidade que atua diretamente no desenvolvimento do programa, promovendo constantes facilidades, melhorias e inovações acessíveis ao público em geral. O compartilhamento de um conjunto de funções é dado através de pacotes, os quais devemos instalar para podermos utilizá-los. Detalharemos a instalação de pacotes na seção 2.4.
E, justamente, uma das principais contribuições idealizadas é o RStudio. O RStudio é uma IDE (Integrated Development Environment), ou seja, um ambiente de trabalho que executa o R a partir de uma interface gráfica mais agradável e com diversas funcionalidades (Figura 2.3), o que nos proporciona um maior conforto quando comparado ao R original, composto basicamente pelas janelas de script e console, como mostra a figura 2.2.
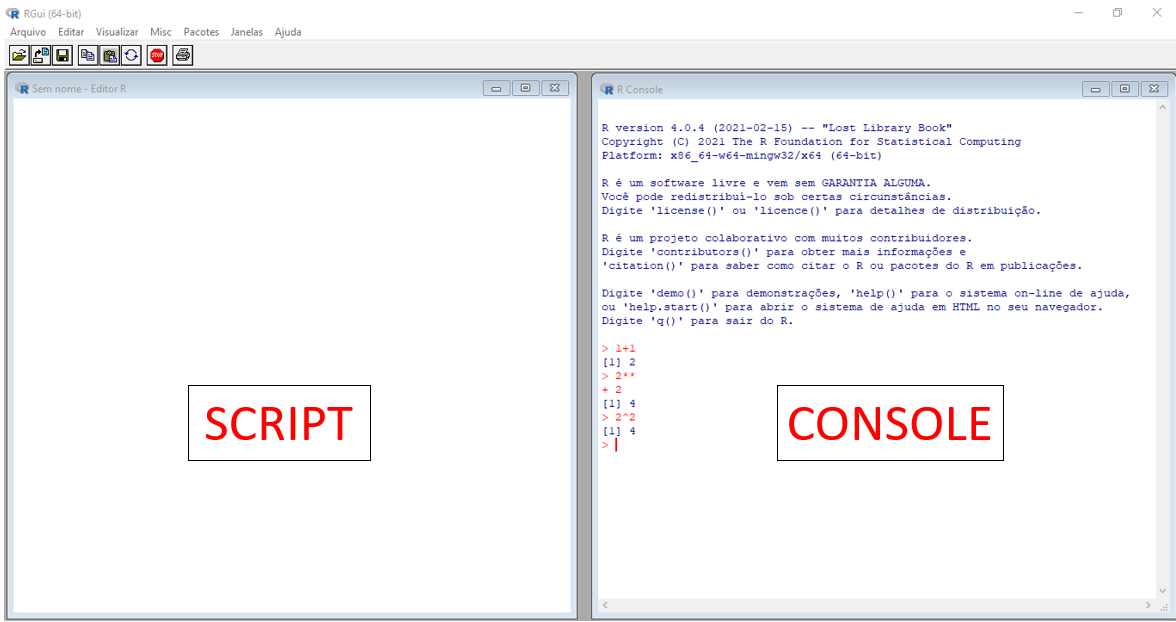
Figure 2.2: Tela do R original. Composto apenas pelo script e console.
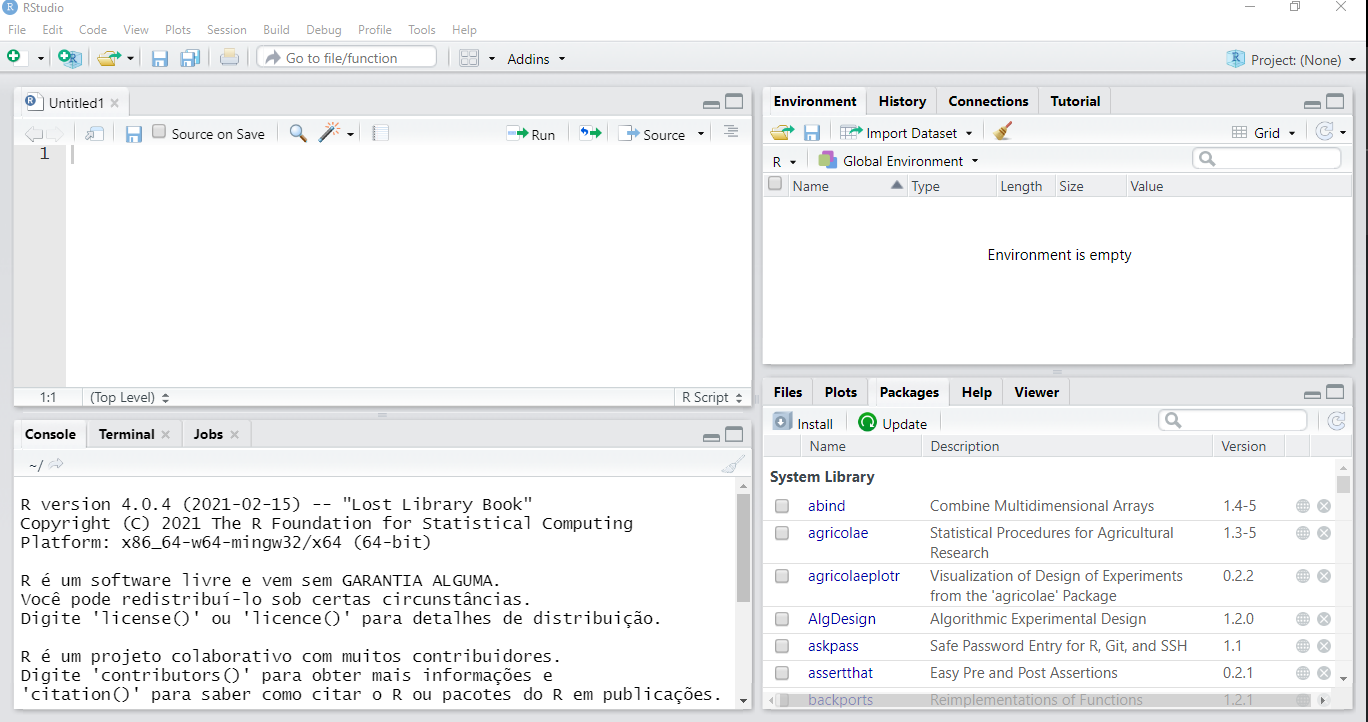
Figure 2.3: Tela do RStudio. Como podemos perceber, bem diferente do R original.
Mais adiante, na subseção 2.2.3, entraremos em mais detalhes sobre o ambiente do RStudio.
Vale salientar que o R pode ser utilizado sem o RStudio, porém o RStudio não funciona sem o R. No nosso caso, utilizaremos o RStudio para desenvolver nossas análises. Assim, precisamos ter instalados ambos os programas.
2.2.1 Instalando o R
O R está disponível para todos os sistemas operacionais. Sua instalação é feita via CRAN (Comprehensive R Archive Network), ou seja, uma rede com diversos servidores localizados em várias regiões do mundo, os quais armazenam versões idênticas e atualizadas de códigos e documentações para o R. Assim, para instalar o R, recomenda-se selecionar o servidor mais próximo à sua região. A seguir está o passo a passo para o download.
Acessar: https://www.r-project.org/;
No canto superior esquerdo, clicar em CRAN;
Selecionar o servidor (mirror) mais próximo a você (perceba que há um servidor da ESALQ/USP-Piracicaba);
Escolha o link referente ao seu sistema operacional;
Sistemas operacionais:
Windows: após clicar em ‘Download R for Windows’, selecione a opção ‘base’ e, posteriormente, ‘Download R x.x.x for Windows’, sendo ‘x.x.x’ a versão mais recente a ser baixada;
Linux: após clicar em ‘Download R for Linux’, selecione a distribuição que você utiliza e siga as instruções da página para instalar o R;
MacOS: após clicar em ‘Download R for macOS’, selecione a opção mais recente do R, a partir do link ‘R-x.x.x.pkg’, sendo ‘x.x.x’ a versão mais recente a ser baixada;
- Feito o download, abra o arquivo baixado e siga as instruções para a instalação. Uma vez que utilizaremos o R a partir do RStudio, não há necessidade de criar um ícone de inicialização do R na área de trabalho, portanto, apenas instale o R em seu computador.
2.2.2 Instalando o RStudio
Uma vez feita a instalação do R, precisamos instalar o RStudio. Também está disponível para todos os sistemas operacionais e sua instalação pode ser feita a partir do link: https://www.rstudio.com/products/rstudio/download/#download. Escolha a versão referente ao seu sistema operacional e siga as instruções para baixar a IDE em seu computador.
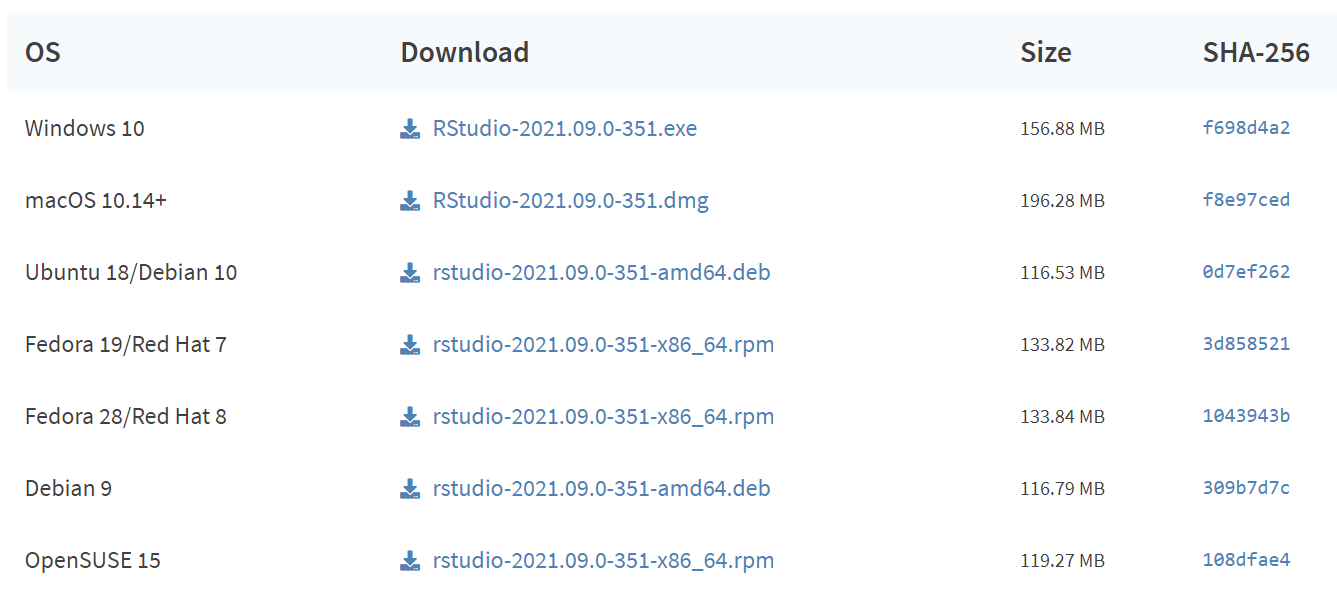
Figure 2.4: Na página referente ao link acima, vá até a seção ilustrada na figura. Lá encontraremos as versões disponíveis do RStudio, de acordo com o sistema operacional.
2.2.3 Ambiente RStudio
Agora que temos o R e o RStudio instalados, vamos conhecer mais sobre o ambiente do RStudio.
Janelas
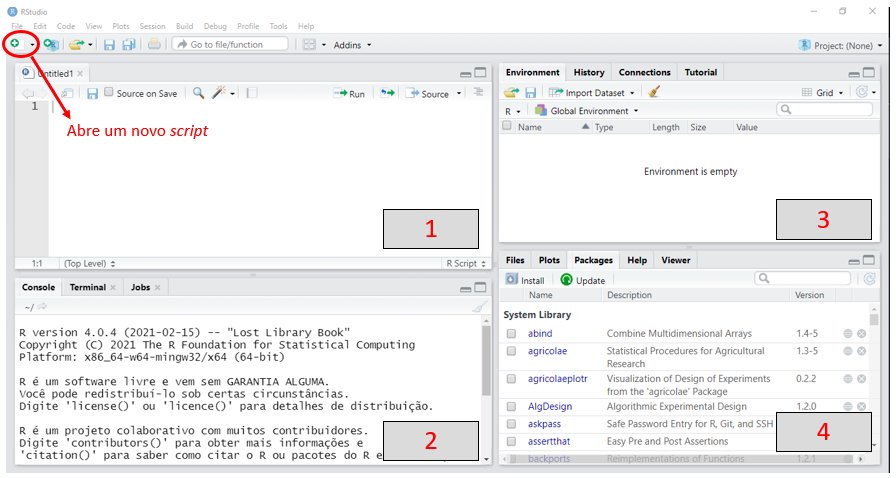
Figure 2.5: O RStudio apresenta 4 janelas principais, algumas com abas específicas, cada qual apresentando funcionalidades particulares.
A figura 2.5 ilustra as quatro janelas presentes no RStudio, cada qual com suas particularidades e funções.
Script: é a janela na qual escreveremos os códigos e comandos. Para abrir um novo script, clique no ícone logo abaixo da aba file, no canto esquerdo superior;
Console: é onde o código roda e apresenta as saídas dos códigos redigidos no script. Também podemos escrever comandos no console, porém, ao contrário do script, não há a possibilidade de edição, sendo necessário reescrevê-lo, caso preciso.
Environment: é onde se localiza e armazena os objetos criados. O ícone da vassoura (presente ao lado do ícone
Import Dataset) exclui os objetos criados. Esta janela contém outras abas, porém a Environment é a principal dentre essas.File, Plots, Packages, Help e Viewer: esta janela contém cinco abas.
File: apresenta os arquivos presentes no diretório do seu computador;
Plots: permite a visualização dos gráficos gerados;
Packages: mostra todos os pacotes instalados em seu RStudio;
Help: retorna documentações referentes a funções as quais podemos saber mais detalhes sobre elas;
Viewer: apresenta os resultados gerados a partir do R Markdown, Bookdown, dentre outras extensões relacionadas a execução de relatórios e documentos diversos.
Aparência
Podemos alterar a aparência do RStudio acessando a aba Tools, presente no menu superior, clicar em Global Options... e, posteriormente, na aba Appearance. Nela, pode-se alterar o tema de fundo, regular o zoom do ambiente como um todo ou somente dos textos e alterar a fonte dos textos. Na figura 2.6 esta ilustrado um exemplo de configuração da aparência do RStudio, e na figura 2.7, o resultado dessa alteração.
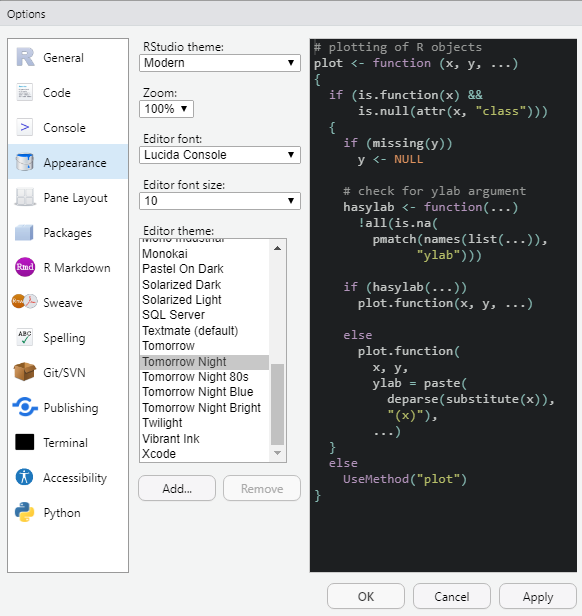
Figure 2.6: Podemos configurar a aparência do RStudio em diversos aspectos. Faça alguns testes e veja qual lhe agrada mais.
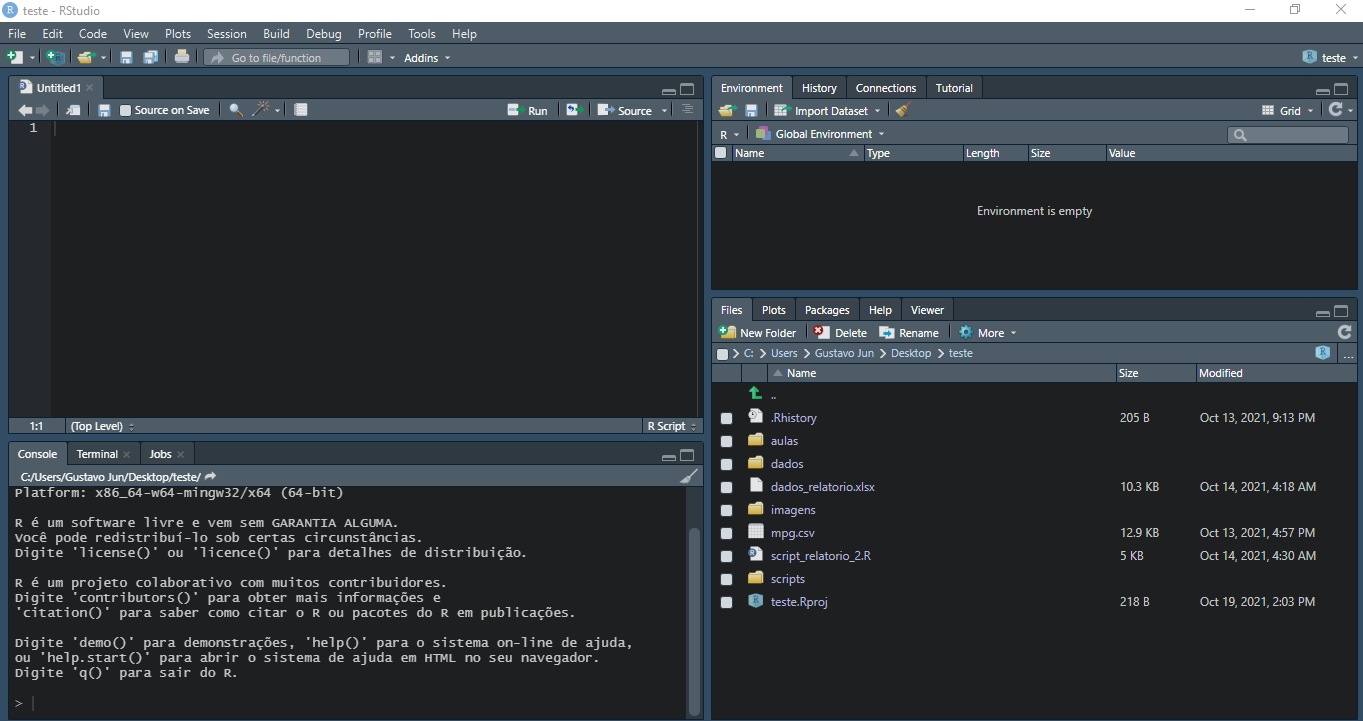
Figure 2.7: Um exemplo de alteração na aparência do RStudio.
2.3 Etapas da Ciência de Dados
Agora que temos uma melhor noção sobre ciência de dados e o software R, vamos explorar as etapas que compõem o seu processo.
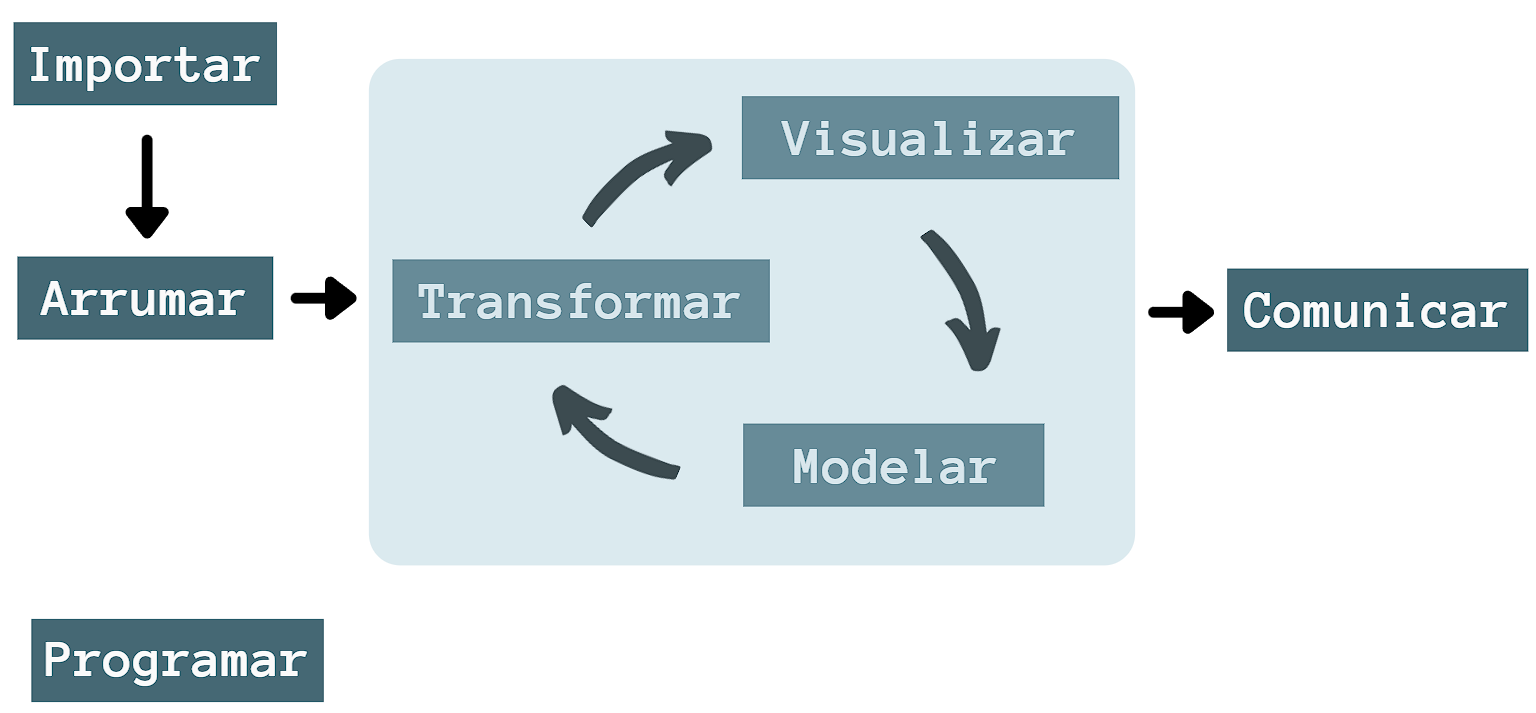
Figure 2.8: Etapas do trabalho em ciência de dados. O ato de programar abrange todos os processos do fluxograma.
O fluxograma da figura 2.8 representa as etapas que compõem o trabalho de um cientista de dados. A seguir, descreveremos brevemente as etapas, para termos noção sobre a relevância de cada uma delas.
Importar (Import): é a importação dos dados brutos para dentro do R, seja a partir de banco de dados presentes na web ou coletados pelo próprio cientista de dados. Basicamente é a etapa sine qua non da ciência de dados, pois sem dados, não há o que analisar;
Limpar/Arrumar (Tidy): limpar ou arrumar os dados significa organizá-los em uma estrutura consistente, que esteja de acordo com a semântica de um conjunto de dados, para que não haja problemas ao realizar as análises. Mais adiante, veremos como estruturar os dados de maneira desejável, designando cada variável a uma coluna e cada observação a uma linha, semalhante a uma planilha Excel;
Transformar (Transform): a transformação consiste em selecionar as observações de interesse no banco de dados. Em outras palavras, reduzir o banco de dados para conter somente as informações necessárias para a análise. Também podemos criar novas variáveis em função das variáveis já existentes, além de gerar descrições estatísticas como média, variância, porcentagens, dentre outras;
Visualizar (Visualisation): a visualização gráfica dos dados permite enxergar as informações com mais clareza, levantar novos questionamentos e até mesmo indicar se a pesquisa está no caminho correto ou não;
Modelar (Models): os modelos são usados para responder as perguntas norteadoras, depois que a pergunta norteadora estiver suficientemente precisa. Entra em cena a matemática, estatística e a computação como ferramentas para sua realização.
Comunicar (Communication): é a parte crítica de um projeto analítico (Data analysis), pois é necessário expor os resultados de maneira inteligível para o público, seja ele técnico ou leigo;
Programar (Programming): a programação abrange todas as etapas citadas anteriormente. Em ciência de dados, não precisamos ter um domínio avançado para começarmos um projeto, mas quanto mais se sabe, mais automático ficam as tarefas comuns e mais facilmente se resolve novos problemas.
Por último, podemos destacar o termo Wrangling, que abrange as etapas de Arrumar e Transformar. Traduzindo o termo, podemos entender que essas etapas do processo são, literalmente, uma luta para que se consiga deixar os dados de forma mais natural para serem analisados.
Na seção 2.4, vamos conhecer mais sobre o pacote tidyverse, o qual contém as principais funções a serem utilizadas ao longo desta apostila. Detalharemos os pacotes específicos para cada uma das etapas descritas anteriormente.
2.4 Pacote tidyverse
O tidyverse é um “pacote mestre” que abrange diversos outros, cada qual apresentando diversas funcionalidades específicas para cada uma das etapas apresentadas no fluxograma do tópico anterior. O esquema a seguir relaciona as etapas que constituem o trabalho do cientista de dados com os respectivos pacotes.
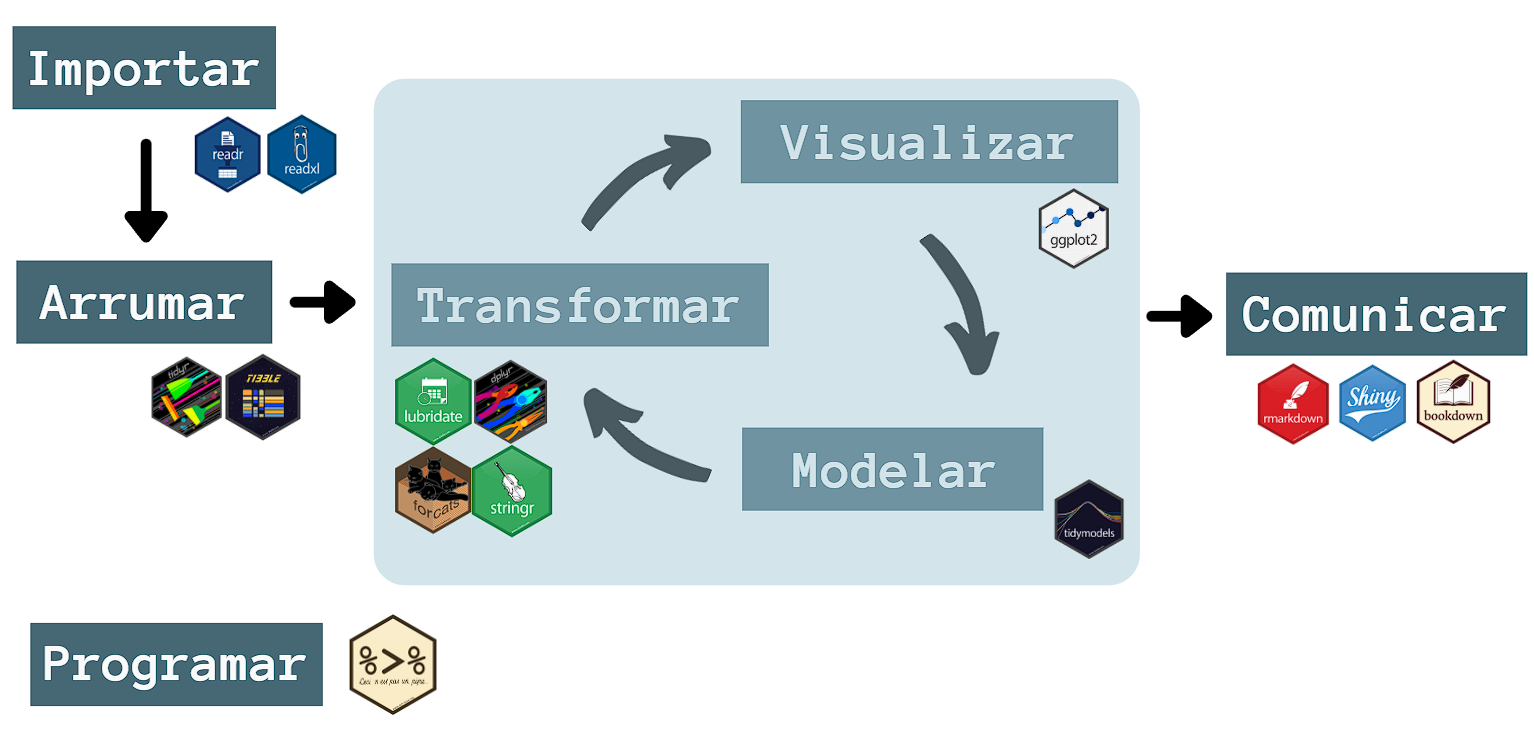
Figure 2.9: Para cada etapa do fluxograma de trabalho da ciência de dados, existem pacotes específicos no R.
Nesta apostila, focaremos no pacote tidyverse aplicado às etapas de Importar, Arrumar, Transformar e Visualizar, apresentando as principais ferramentas a serem utilizadas. Apenas os pacotes relacionados às etapas de Modelar e Comunicar não estão presentes no tidyverse.
Assim sendo, vamos instalar o nosso primeiro pacote, o tidyverse:
A função install.packages("nome_do_pacote") instala o requerido pacote. Atente-se ao fato que o nome do pacote deve estar entre aspas.
Uma vez instalado, devemos carregar o pacote com a função library(), para que possamos utilizar as suas funcionalidades. Agora, o nome do pacote não precisa estar entre aspas. Esta função deve ser executada a cada nova seção inicializada no R.
Lembrando que, para executar um comando, devemos escrever os respectivos códigos no script ou no console.
Para rodar estas funções (além das demais outras que rodaremos), devemos selecionar a linha de código que se deseja executar e clicar no ícone ‘Run’, presente no canto superior direito da própria janela do script, ou utilizar o atalho ctrl + Enter no teclado. Perceba que temos que rodar linha por linha de código ou selecionar todas as linhas do script para então rodar o código de uma vez só.
Para se ter uma visão geral de quais pacotes estão presentes no tidyverse, utilizamos a função tidyverse_packages().
[1] "broom" "cli" "crayon" "dbplyr"
[5] "dplyr" "dtplyr" "forcats" "ggplot2"
[9] "googledrive" "googlesheets4" "haven" "hms"
[13] "httr" "jsonlite" "lubridate" "magrittr"
[17] "modelr" "pillar" "purrr" "readr"
[21] "readxl" "reprex" "rlang" "rstudioapi"
[25] "rvest" "stringr" "tibble" "tidyr"
[29] "xml2" "tidyverse" Perceba que o pacote tidyverse contém outros 30 pacotes. Dentre estes, utilizamos o readr e o readxl para importarmos os dados; o tidyr e o tibble para arrumar; o dplyr, stringr, forcats e lubridate para transformar; e por último, o ggplot2 para visualizar.
Caso o leitor tenha curiosidade em saber mais detalhes sobre o tidyverse, acesse o link da página oficial do pacote: https://www.tidyverse.org/packages/.
Nos capítulos a seguir, abordaremos as etapas de Importar, Arrumar, Transformar e Visualizar, apresentando as principais utilidades e funções de cada um dos respectivos pacotes presentes no tidyverse. Mas antes, veremos alguns conceitos básicos para programarmos em R.